DBMS 아키텍쳐 개요
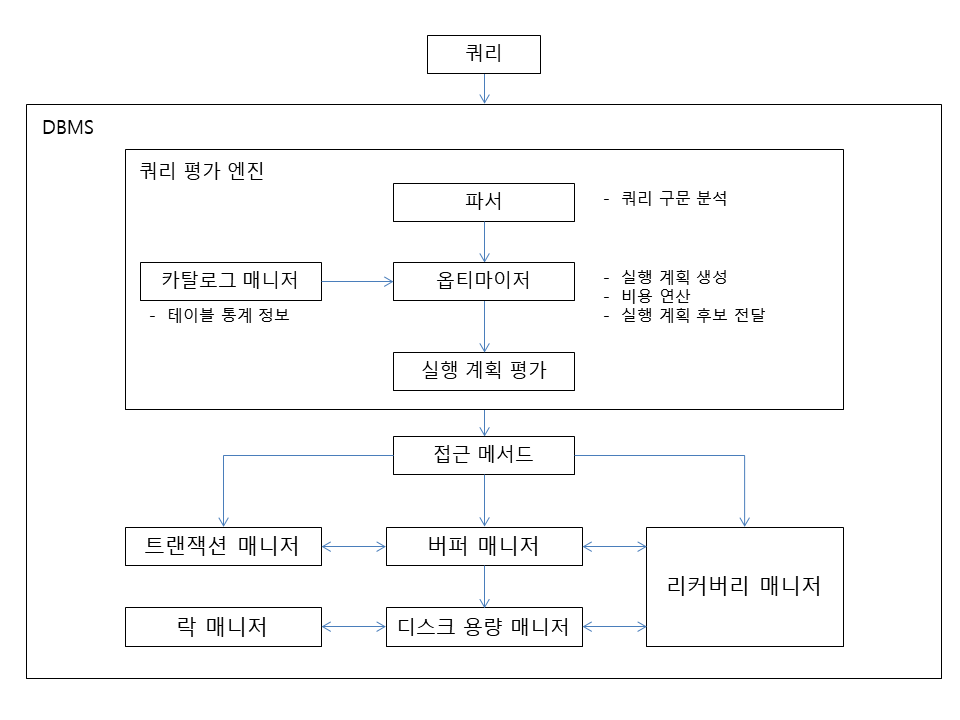
쿼리 평가 엔진
쿼리 평가 엔진은 사용자로부터 입력받은 SQL 구문을 분석하고, 어떤 순서로 기억장치의 데이터에 접근할지를 결정하는데 이 때 결정되는 계획을 '실행 계획'이라고 한다. 이러한 실행 계획에 기반을 둬서 데이터에 접근하는 방법이 '접근 메서드'이다. 한마디로 쿼리 평가 엔진은 계획을 세우고 실행하는 DBMS의 핵심 기능을 담당하는 모듈이다.
실행 계획
실행 계획이 만들어지면 DBMS는 그것을 바탕으로 데이터 접근을 수행한다. 하지만 데이터양이 많은 테이블에 접근하거나 복잡한 SQL 구문을 실행할 경우 옵티마이저가 최적의 실행 계획을 선택하지 못할 수 있다. 이처럼 SQL 구문의 지연이 발생했을 때는 다음 명령어를 통해 실행 계획을 확인한다.
| DBMS | 명령어 |
| Oracle | set autotrace traceonly SQL구문 |
| MS SQL Server | set showplan_text on SQL구문 |
| PostgresSQL | explain SQL구문 |
| MySQL | explain extended SQL구문 |
실행 계획 확인하기 (with PostgreSQL)
1) 풀 스캔 실행 계획
EXPLAIN
SELECT *
FROM REVIEWS;
결과

이는 'reviews' 테이블에 대해 '순차적으로 접근'하여 '전체 99224 rows의 데이터'를 읽어낸다는 의미로 해석할 수 있다. 특히 레코드 수는 각 조작에서 얼마만큼의 레코드가 처리되는지 SQL 구문 전체의 실행 비용(cost)을 파악하는데 중요한 지표가 된다. 단 레코드 수, 또는 실행 비용은 절대 지표로써 판단하기는 어렵다. 가령 "이 SQL 구문은 cost가 5000 밖에 되지 않으니까 1초 이내로 끝나겠다"라는 추측은 할 수 없는 것이다.
※ 실행 계획의 레코드 수 ≠ 테이블 레코드 수
실행 계획의 레코드 수는 옵티마이저가 실행 계획을 만들 때 설명했던 카탈로그 매니저로부터 얻은 값입니다. 따라서 통계 정보에서 파악한 숫자이므로 실제 SQL 구문을 실행한 시점의 테이블 레코드 수와 차이가 있을 수 있습니다.
예를 들어 테이블의 모든 레코드를 삭제하고 실행 계획을 다시 검색하면 이전과 같은 값이 출력됩니다. 이는 옵티마이저가 어디까지나 통계라는 메타 정보를 믿기 때문에 실제 테이블을 제대로 보지 않는다는 증거입니다.
2) 인덱스 스캔 실행 계획
EXPLAIN
SELECT *
FROM REVIEWS
WHERE ORDER_ID = 'df56136b8031ecd28e200bb18e6ddb2e';
결과

위 실행 계획은 'reviews' 테이블에 대해 'pk_reviews 인덱스를 사용해 스캔을 수행'하여 '1 rows의 데이터'를 읽어낸다는 의미로 해석할 수 있다. WHERE 절에서 ORDER_ID를 지정했으므로 접근 대상은 레코드 하나가 된다.
인덱스 스캔은 데이터가 많을수록 테이블 풀 스캔보다 빠르게 데이터 접근을 수행한다. 이는 풀 스캔의 경우 모집합의 데이터 양에 비례해서 처리 비용이 늘어나는 것에 반해, 인덱스 스캔에서 사용되는 B-tree 구조의 경우 처리 비용이 완만하게 증가하기 때문이다.

3) 조인 실행 계획
EXPLAIN
SELECT CUSTOMER_ID
FROM ORDERS O JOIN REVIEWS R ON O.ORDER_ID = R.ORDER_ID;
결과

위 실행 계획은 '먼저 orders 테이블, 그 다음 review 테이블'에 대해 '순차적으로 접근'하여 각각 '99441 rows, 99224 rows의 데이터'를 읽어낸 후 '결합 키 값을 해시 값으로 매핑'하여 결합한다는 의미로 해석할 수 있다. 실행 계획은 일반적으로 트리 구조를 가지며 중첩 단계가 깊을수록 먼저 실행된다. 따라서 hash join보다 seq scan이 먼저 수행되고, 동등 중첩 단계 내에서는 위에서 아래로 실행되므로 orders 테이블에 대한 접근이 먼저 이루어진다.
버퍼 매니저
일반적으로 기억장치는 기억 비용에 따라 1차부터 3차까지의 계층으로 분류할 수 있다. 그 중 메모리는 1차 기억장치로 2차 기억장치인 디스크에 비해 기억 비용이 비싸다. 그렇지만 DBMS가 일부라도 데이터를 메모리에 올리는 것은 성능 향상, 즉 SQL 구문의 실행 속도를 빠르게 만들기 위함이다.
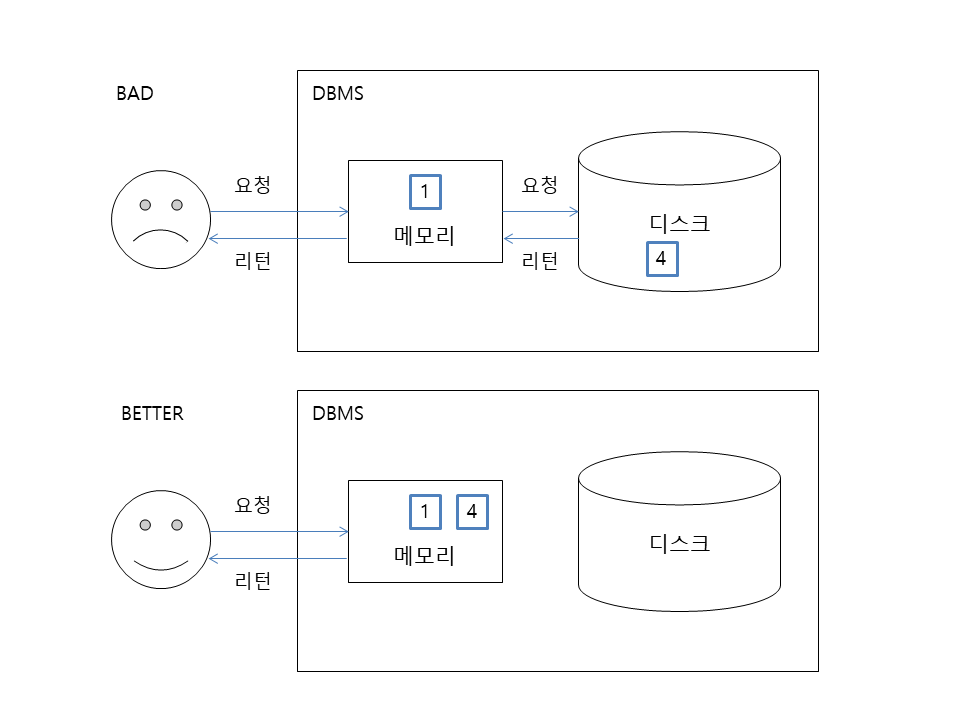
이렇게 성능 향상을 목적으로 데이터를 저장하는 메모리를 버퍼 또는 캐시라고 부른다. 그리고 이처럼 고속 접근이 가능한 버퍼에 데이터를 어떻게, 어느 정도의 기간 동안 올릴지 관리하는 것이 DBMS 버퍼 매니저의 역할이다.
버퍼의 종류
1) 데이터 캐시(→ 검색 처리)
데이터 캐시는 디스크에 있는 데이터의 일부를 메모리에 유지하기 위해 사용하는 메모리 영역이다. 가령 SELET 구문에서 조회하려는 데이터가 모두 데이터 캐시에 있다면 디스크에 접근하지 않고 검색 처리를 수행할 수 있다.
2) 로그 버퍼(→ 갱신 처리)
로그 버퍼는 갱신 처리(삽입, 삭제, 갱신, 병합)를 수행하는 메모리 영역이다. DBMS는 갱신과 관련된 SQL 구문을 사용자로부터 받으면 곧바로 디스크에 있는 데이터를 변경하지 않고 일단 로그 버퍼 위에 변경 정보를 보낸 이후 디스크의 데이터를 변경하는 비동기 처리를 수행한다.
3) 워킹 메모리(→ 정렬, 해시 결합 처리)
워킹 메모리는 정렬 또는 해시 결합 처리를 수행하는 메모리 영역이다. 정렬은 ORDER BY, 집합 연산, 윈도우 함수 등의 기능이 사용될 때, 해시는 테이블 등의 결합에서 해시 결합이 사용될 때 실행된다. 이 영역이 성능적으로 중요한 이유는 다루려는 데이터양이 커져 해당 메모리의 공간이 부족해지면 디스크의 임시 영역을 대신 사용하기 때문이다. 이러한 임시 영역들은 디스크 위에 있으므로 접근 속도가 순간적으로 저하되는 문제가 발생할 수 있다.
※ 로그 버퍼 휘발성의 문제
로그 파일에 전달된 갱신 정보가 DBMS가 다운될 때 사라지는 현상은 DBMS가 갱신을 비동기로 하는 이상, 언제든 발생할 수 있는 문제입니다. 따라서 이를 회피하고자 DBMS는 커밋 시점에 반드시 갱신 정보를 로그 파일(이는 영속적인 디스크 위에 존재)에 씀으로써, 장애가 발생해도 정합성을 유지할 수 있게 합니다.
※ 데이터 캐시 VS 로그 버퍼
메모리라는 비싼 희소 자원으로 모든 것을 커버하기에는 부족합니다. 따라서 어떤 처리를 우선으로 할지 결정해야 하는데, 데이터베이스는 기본적으로 검색을 메인으로 처리한다고 가정하여 로그 버퍼보다 데이터 캐시에 더 많은 메모리를 할당하는 것을 기본으로 합니다.
정리
쿼리 평가 엔진은 SQL문을 읽어들여 실행 계획을 작성하고 이들의 비용을 연산하여 가장 낮은 비용을 가진 실행 계획을 선택하는데, 이러한 과정은 데이터 접근 방법을 최적화하기 위함이다.
또한 버퍼 매니저는 고속 접근이 가능한 버퍼에 데이터를 어떻게, 어느 정도의 기간 동안 올릴지 관리하는 역할을 하므로 버퍼 매니저 역시 데이터베이스의 성능에 중요한 영향을 끼친다.
만약 잘못된 실행 계획이 생성 및 선택되어 성능이 저하될 경우 직접 실행 계획을 튜닝해주어야 하는데 이를 위해 실행 계획을 읽고 SQL 구문이 어떤 접근 경로로 데이터를 검색하는지 알아야 한다.
위 내용은 <SQL 레벨업 DB 성능 최적화를 위한 SQL 실전 가이드>을 참고하여 작성한 내용입니다
참고
Big-O: how code slows as data grows
Created 18 October 2017 There’s this thing in computer science that working programmers talk about, called “big-O”. When a software developer feels bad because they don’t have a Computer Science degree, and they feel a bit inferior because of it, i
nedbatchelder.com
'CS 기초 > 데이터베이스' 카테고리의 다른 글
| [성능 개선] 데이터베이스 튜닝의 시작, 인덱스 활용하기 (0) | 2023.05.24 |
|---|---|
| [성능 개선] 결합을 지배하는 자가 성능을 지배한다 (1) | 2023.05.21 |
댓글