데이터를 잘 다루기 위해서는 어디에, 어떤 데이터가 있는지 속속들이 파악하는 것이 먼저인 것 같다는 생각이 드는 요즘. 이런 걸 EDA라고 멋들어지게 말하던데 화려한 시각화까지는 아니더라도 나만의 EDA 방법을 매뉴얼화 해보려고 한다.
(언제나 그렇듯 근본없음. 내가 보려고 만듦. 그리고 약간의 파이썬을 곁들인..)
1. 요구사항 정의
우리 쇼핑몰에서는 단가가 높은 상품이 많이 나가는지, 단가가 낮은 상품 위주로 판매되는지 알고 싶다는 니즈에서 출발해본다. 먼저 위와 같이 자연어로 이루어진 요구사항을 데이터 추출에 용이한 문장으로 재작성한다.
예시로 든 상황에서도 오해의 소지가 많은데 가령 가장 많이 팔린 상품의 판매가를 말하는 건지, 전체 주문 상품 판매가의 평균을 말하는 건지 등 다양한 의미로 해석될 수 있으므로 데이터 활용 목적에 기반하여 요청자와, 혹은 자신과의 논의가 필요하다.(여기서는 후자로 가정한다.)
→ 월별 주문 상품 판매가의 평균 금액은?
2. 데이터 파악
앞서 정의한 요구사항 문장을 도메인 단위로 쪼개어 예상되는 테이블과 컬럼이 존재하는지 찾아본다. 일단 가장 작은 단위부터 생각해보면 판매가는 상품 정보 중 하나이므로 상품 테이블에서 찾아볼 수 있을 것이다.(아닐수도 있다!)그리고 월별 주문 정보는 주문일시에 대한 정보를 통해 도출해야 하므로 누가, 언제, 어디서, 어떻게 주문했는지에 대해 확인할 수 있는 주문 테이블을 찾아볼 수 있을 것이다.
→ 월별 / 주문 / 상품 / 판매가의 / 평균 금액은? → 주문 테이블과 주문일시 컬럼, 상품 테이블과 판매가 컬럼을 찾아본다
상식적인 수준에서 테이블과 컬럼의 위치를 추론했다 하더라도 정확한 컬럼명도 모르고 실제 그 컬럼이 그 테이블에 존재하는지도 모르는 상태이므로 데이터의 일부를 조회해본다. 다른 EDA 자료들, 특히 파이썬 EDA에서는 컬럼들을 확인하기 위해 .columns를 활용하는 경우를 많이 봤는데 개인적으로는 value와 컬럼을 같이 봤을 때 테이블을 더 빨리 이해할 수 있어서 .sample()을 선호하게 되었다.
# SQL
select *
from order
limit 10
select *
from product
limit 10
# python
order.sample(10)
product.sample(10)
→ 주문 테이블에는 주문 건별 정보가 들어있다 → 상품 테이블에는 공급가와 판매가, 부가세 정보가 들어있다 → 주문 건 내에 어떤 상품을 주문했는지 확인하기 위해 주문 상세 내역이 필요하다
주문 테이블과 상품 테이블을 각각 조회했을 때 각각 주문과 상품에 대한 정보는 확인할 수 있지만 주문 건별로 어떤 상품을 주문했는지는 알 수 없다. 이로써 주문 상품에 대한 정보를 확인하기 위해서는 두 테이블 간의 연관 관계를 찾아내거나 새로운 테이블을 찾아야 한다는 사실을 알 수 있다. (즉, 주문 상세 테이블이 존재하는 상황)
3. 샘플링
위에서 데이터의 일부를 조회하는 것과 비슷한 맥락인데 이번에는 테이블의 구성, 컬럼 간의 관계를 파악하기 위해 특정 조건을 부여해서 데이터를 조회해본다. 이렇게 하면 제시한 조건이나 상황에서 데이터가 어떻게 생성되는지 맥락을 이해하는데 도움이 된다.
가령 유저 아이디를 조건으로 주문 상세 내역을 조회해보면 주문이 완료되는 시점에 생성되는 데이터들은 무엇이 있는지, 주문을 구성하는데 반드시 필요한 데이터가 무엇인지, 주문과 관련이 있다고 생각했는데 주문 상세 테이블에 없는 컬럼이 있는지 등을 파악할 수 있다.
# SQL
select *
from order_detail
where order_Id in (select order_Id
from order
where user_Id = 1000)
→ 주문 상세 테이블에는 주문 상품 정보가 들어있다. → 한 건의 주문에는 여러 상품이 존재할 수 있다. 단 상품이 하나도 없는 주문은 존재할 수 없다.
4. 결측치 확인
결측치라고 하면 기본적으로는 N/A값이지만 로직이 빵꾸나거나, 테스트 데이터이거나 등등 어떤 이유에서건 이해가 되지 않는 값이 들어가 있는 경우도 있다.
위 상황에서는 판매가가 0원이거나 N/A 인 경우 구하고자 하는 평균 금액을 연산하기 어려우므로 판매가에 결측치가 있는지 확인이 필요할 것이다. 그리고 만약 결측치가 존재한다면 값을 제외할지, 포함한다면 어떤 값으로 대체할지 결정해주어야 한다. 추가로 내일의 나를 위해서는 왜 결측치가 발생하는지 원인을 파악하고 해결도 해야할 것이다. 이런 방식으로 개발자를 많이 괴롭게 했다(..)
# SQL
select *
from order_detail
where unit_price is null
#python
order_detail.isnull().sum()
결국 종합해보면 로우 데이터를 어느 정도는 눈으로 확인해봐야 완전한 검증이 가능한 것 같다. 특히 파이썬 EDA 관련 자료들을 읽다 보면 데이터의 양의 많아서인지 .describe()로 평균 값을 확인하거나 .hist(), .displot() 과 같은 시각화를 많이 활용하는 것 같았다. 그치만 내 생각에 평균 값만 보고 이상치를 판단할 수 있으려면 좀 더 많은 경험과 도메인 지식이 필요할 것 같다. (”평소보다 값이 너무 큰데?/작은데?” 등을 직관적으로 판단하고 추가 검증 여부를 결정할 수 있는)
+ 내용 추가
상사에게 "이 데이터 좀 봐줄래요?" 라는 말을 들었을 때 해야할 일
요구사항 정의, 데이터 파악, 샘플링, 결측치 확인 그 다음엔 뭘 해야할까?
데이터사이언티스트 이지영님의 강의를 듣고 내용을 보충해보았다.
아래 내용은 데이터사이언티스트 이지영님의 유튜브 '비전공자도 할 수 있는 파이썬 데이터 분석 핵심편'을 토대로 작성한 내용입니다.
2. 데이터 파악
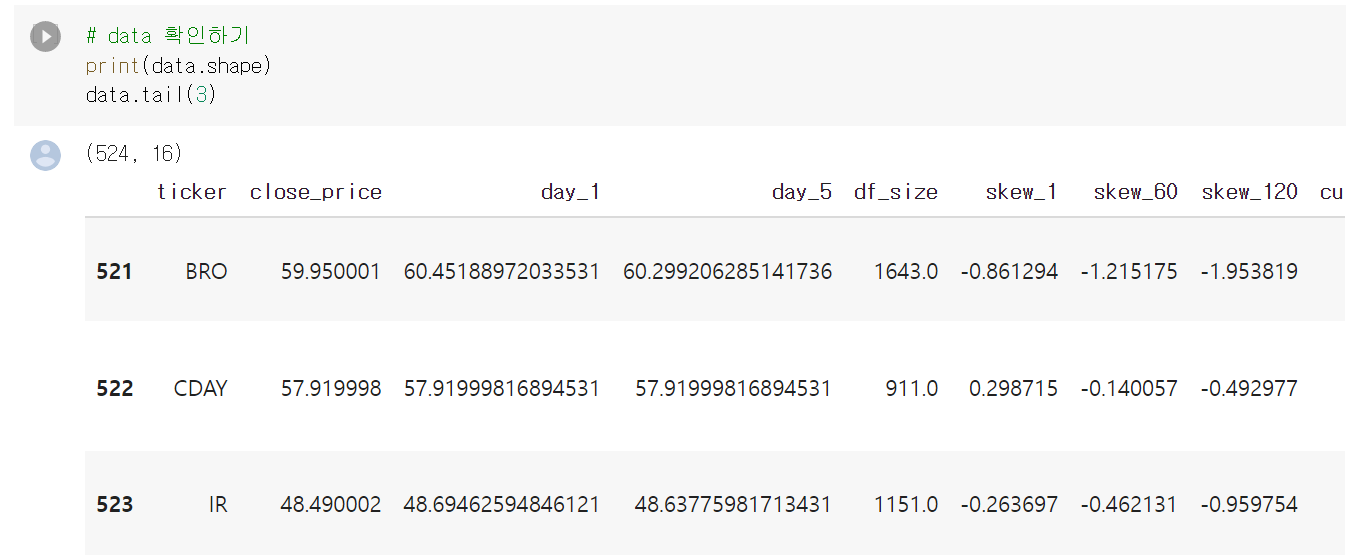
데이터의 행, 열 크기 확인하기
# 데이터 크기
data.shape
data.shape[0]
# 또는
len(data)
4. 결측치 확인
결측량의 비율 구하기
# 결측치 퍼센티지
# 모든 열, 각 행마다 그 값이 isnull인지 True/False로 확인한 후,
# True인 값을 더하고, 더한 값을 전체 데이터 크기로 나눔
data.isnull().sum()/len(data)*100
# 또는
data.isnull().mean()*100
특정 열의 결측치인 데이터만 보기
# 결측치가 있는 데이터 확인하기
data[data["sector"].isnull()]
결측치 제거하기
# 특정 컬럼에서 결측값이 있을 경우 그 행을 제거
# 그 결과를 다시 data라는 이름으로 덮어 씀(inplace=True)
data.dropna(subset=['industry', 'sector'], inplace=True)
# implace 대신
data = data.dropna(subset=['industry', 'sector'])
# 특정 값을 지운 경우 데이터 크기를 다시 확인
data.shape
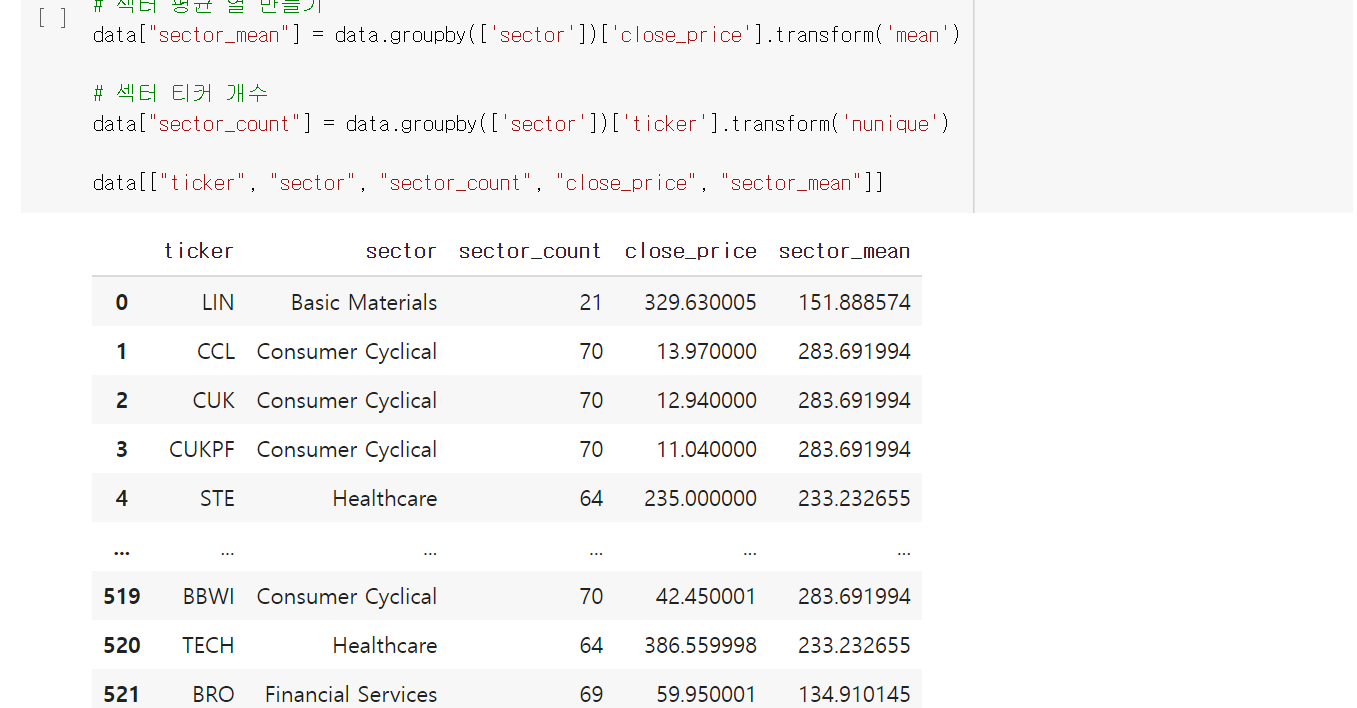
5. 중복값 확인
특정 열의 유일한 값 갯수 구하기
# 전체 행의 갯수와 특정 열의 유일값의 갯수를 비교하면 중복값이 있는지 확인할 수 있음
# 전체 행의 갯수
len(data)
# 특정 열의 유일값의 갯수
len(data["ticker"].unique())
# 또는
data["ticker"].nunique()
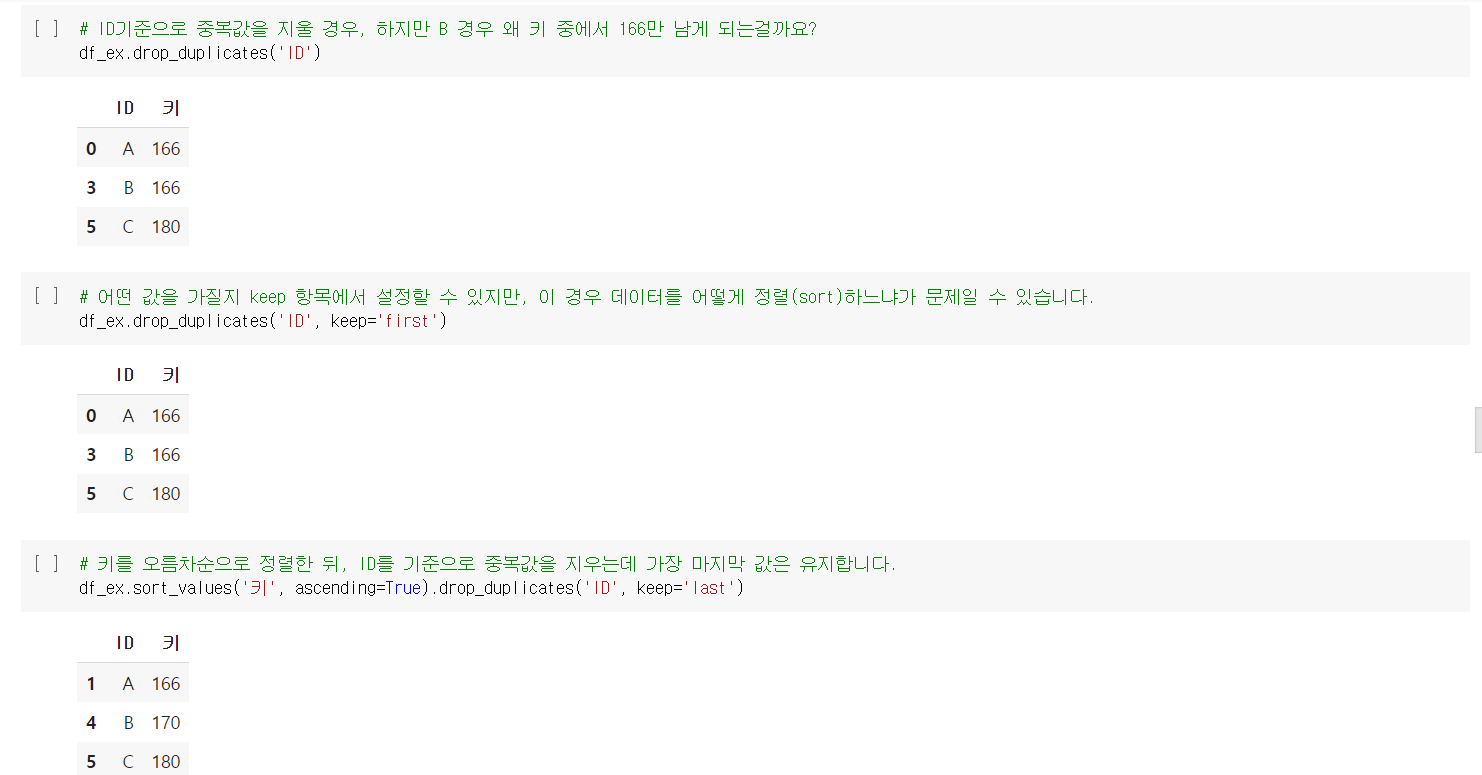
중복값 제거하기 - 어떤 기준으로 중복값을 제거할 것인가?
# 데이터 프레임 예시
df_ex = pd.DataFrame({"ID":["A", "A","A", "B", "B", "C"],
"키":[166,166, 150, 166, 170, 180]})
# 중복되는 ID가 있을 경우 ID가 유일하게 남도록 중복값을 지움
df_ex.drop_duplicates('ID')
# 어떤 값을 가질지 keep 항목에서 설정할 수 있지만 이 경우 정렬 작업이 선행되어야 함
df_ex.drop_duplicates('ID', keep='first')
# 키를 오름차순으로 정렬한 뒤 ID를 기준으로 중복값을 지우는데 가장 마지막 값을 유지
df_ex.sort_values('키', ascending=True).drop_duplicates('ID', keep='last')
# 인덱스 리셋하기
df_ex.sort_values('키', ascending=True).reset_index()











댓글