이 정도 수치면 그룹 내에서 높은걸까? 낮은걸까?
→ 각 데이터 값의 그룹 내 위치, 중요도, 우선순위 등을 알아보자
[Step 1] 수치형 데이터의 구간 나누기
pd.qcut(data['close_price'], 3).value_counts()
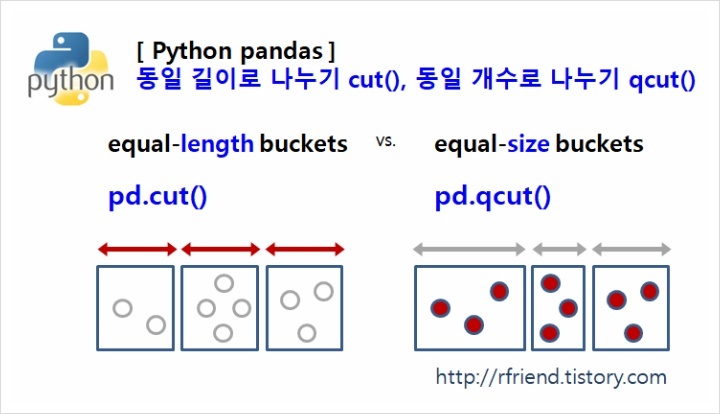
pd.cut(data['close_price'], 3).value_counts()qcut()과 cut() 함수
-> cut은 절대평가, qcut은 상대평가출처: [Python Pandas] 동일 길이로 나누어서 범주 만들기 pd.cut(), 동일 개수로 나누어서 범주 만들기 pd.qcut()
[Step 2] 나누어진 구간에 라벨링하기
pd.qcut(data['close_price'], 3, labels = ['L', 'M', 'H'])
pd.cut(data['close_price'], 3, labels = ['L', 'M', 'H'])[Step 3] 라벨링한 값을 새로운 열로 추가하기
data['close_price_group'] = pd.qcut(data['close_price'], 3, labels = ['L', 'M', 'H'])
data[["ticker", "sector", "close_price", "sector_mean", "close_price_group"]]
-> 라벨링한 값은 전체 close_price 를 기준으로 그룹지어 라벨링한 것이기 때문에 sector를 기준으로 group by 가 한 번 더 필요하다
[Step 4] 그룹별 구간 데이터 라벨링
data["price_s_level"] = data.groupby(['sector'])['close_price'].\
transform(lambda x: pd.qcut(x, 3, labels = ['L', 'M', 'H']))
data[["ticker", "sector", "sector_count", "sector_mean", "close_price", "price_s_level"]]-> sector 열을 기준으로 group by() 하고 close_price 열에 대해 계산한 값을 새로운 열로 추가(transform())한다. 이 때 close_price 열에 대해 동일 갯수로 나눠주는 계산(qcut())을 람다 함수(lambda x:)로 수행한다.

위 내용은 데이터사이언티스트 이지영님의 유튜브 '비전공자도 할 수 있는 파이썬 데이터 분석 핵심편'을 참고하여 작성한 내용입니다.
이걸 SQL로 한다면?
-> NTILE과 WIDTH_BUCKET이 각각 qcut과 cut 에 대응되는 내용인 것 같은데 SQL로도 테스트 필요함!
'데이터 분석 > SQL과 Python' 카테고리의 다른 글
| [SQL] 데이터 정합성 검증하기(2) - 중복값 (0) | 2023.01.02 |
|---|---|
| [SQL] 데이터 정합성 검증하기(1) - 결손값 (0) | 2023.01.02 |
| [SQL] 가로 세로 피봇팅 하기 (0) | 2022.12.17 |
| [SQL&Python] 실전 맨땅에 EDA (0) | 2022.10.08 |
| [SQL] with절과 서브쿼리 (1) | 2022.09.16 |
댓글