유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(1)
유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(2)
유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(3)
데이터 분석을 위한 파이썬 로드맵(내가 보려고 만듦)

데이터 전처리, 탐색
1) 데이터 추출
필요한 속성만 추출
Q. 'math' 컬럼 추출하기
# 시리즈 형태로 추출
s_math = df['math']
# 데이터프레임 형태로 추출
df_math = df[['math']]조건에 따라 추출
Q. kor의 값이 60~90인 학생의 name, kor 추출하기
df[(df['kor']>=60)&(df['kor']<=90)][['name','kor']]Q. 이름이 Amy, Rose인 데이터 추출하기
df[df['name'].isin(['Amy','Rose'])]인덱스, 행번호로 추출
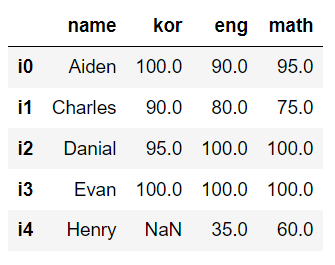
.loc[인덱스]
# 시리즈 형태로 추출
s_Evan = df.loc['i3']
# 데이터프레임 형태로 추출
df_Evan = df.loc[['i3']]
# 인덱스, 컬럼에 해당하는 데이터 한 개 추출
df.loc['i3','kor']>>

>>

>> 100.0
.iloc[행번호]
# 시리즈 형태로 추출
s_Evan = df.iloc[3]
# 데이터프레임 형태로 추출
df_Evan = df.iloc[[3]]
# 행번호, 열번호에 해당하는 데이터 한 개 추출
df.iloc[3,0]>>

>>

>> 'Evan'
2) 결측치 확인/처리
Q. kor이 null인 데이터를 추출하시오
df[df.kor.isnull()]Q. 결측치가 존재하는 모든 행 삭제하기
df.dropna()Q. 결측치 0으로 채우기
df.fillna(0)3) 데이터 형식 변경
인덱스 변경
df.rename(index={100:'a',200:'b'}, inplace=True)자료형 변환
숫자 형변환하기
df = df.astype('float64')
# 자료형이 혼합되어 astype 사용 불가할 경우
pd.to_numeric(s2, errors='ignore')날짜 형변환하기
df['출생'] = df['출생'].astype('datetime64')
df['사망'] = pd.to_datetime(df['사망'])4) 테이블 형태 변경
열 추가/삭제하기
df['sum'] = df['kor']+df['eng']+df['math']
df.drop(columns = ['sum'], inplace=True)행 추가/삭제하기
new_value = {'name':'Python','kor':80,'eng':90,'math':100}
df = df.append(new_value, ignore_index=True)
df.drop(index=[30], inplace=True)데이터프레임 연결하기
# 행으로 연결(아래로)
df_rowconcat = pd.concat([df1,df2,df3])
# 열로 연결(옆으로)
df_column_concat = pd.concat([df4,df5,df6], axis=1)데이터프레임 결합하기
df_merge = pd.merge(df7, df8, on='name')피봇팅하기
df.pivot(index='name', columns='subject', values='score')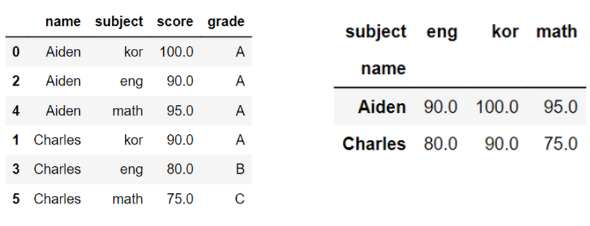
5) 집계
아이템, 사이즈별 재고 합계 피봇테이블로 집계하기
pd.pivot_table(df, index='item', columns='size', values='inventory', aggfunc='sum')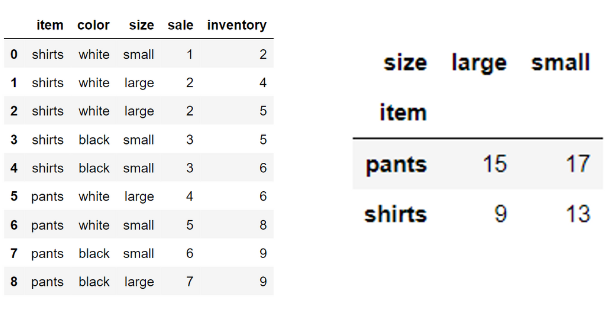
객실등급별 탑승자 수를 데이터프레임 df1으로 만들기
df1 = df.groupby('Pclass').Survived.count().to_frame()
객실등급별 생존자 수를 데이터프레임 df2로 만들기
df2 = df.groupby('Pclass').Survived.sum().to_frame()
객실등급별 생존율을 데이터프레임 df3으로 만들기
df3 = df.groupby('Pclass').Survived.mean().to_frame()
객실등급별 탑승자수, 생존자수, 생존율을 데이터프레임 df4로 만들기
df4 = pd.concat([df1, df2, df3], axis = 1)
df4.columns = ['탑승자수', '생존자수', '생존율']
>> 유데미 바로가기
>> STARTERS 취업 부트캠프 공식 블로그 보러가기
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터 분석 과정 학습 일지 리뷰로 작성되었습니다.
#유데미 #유데미코리아 #유데미큐레이션 #유데미부트캠프 #취업부트캠프 #스타터스부트캠프 #데이터시각화 #데이터분석 #데이터드리븐 #태블로
'유데미 스타터스 데이터 분석' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(4) (2) | 2023.03.10 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(3) (0) | 2023.03.10 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(1) (0) | 2023.03.05 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 3주차 학습 일지 (0) | 2023.02.26 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 2주차 학습 일지 (0) | 2023.02.19 |

댓글