DDL(데이터 정의)
- CREATE (스키마, 테이블 구조 생성)
CREATE TABLE 테이블명{
ID INTEGER PRIMARY KEY,
NAME VARCHAR(20) NOT NULL,
PRICE INTEGER
};
- ALTER (테이블 구조 변경)
# 컬럼 추가
ALTER TABLE 테이블명
ADD 컬럼명 VACHAR(30);
# 컬럼 타입 변경
ALTER TABLE 테이블명
MODIFY 컬럼명 INTEGER;
# 컬럼 삭제
ALTER TABLE 테이블명
DROP COLUMN 컬럼명;
- DROP (테이블 구조 삭제)
DROP TABLE 테이블명;
- RENAME (테이블명 변경)
- TRUNCATE (데이터 모두 삭제)
DML(데이터 조작)
- SELECT(조회)
SELECT 컬럼명
FROM 테이블명
WHERE 조건
GROUP BY 컬럼명
HAVING 조건
ORDER BY 컬럼명
- INSERT(삽입)
INSERT INTO 테이블명(컬럼1, 컬럼2, ...)
VALUES (값1, 값2, ...)
- UPDATE(갱신)
UPDATE 테이블명
SET 속성1 = 값1
WHERE 조건
- DELETE(삭제)
DELETE FROM 테이블명;
DCL(데이터 제어)
- GRANT(권한)
- REVOKE(트랜잭션 제어)
조건문
- WHERE
- 패턴매칭(LIKE)
| 연산자 | 기능 | 예 | 설명 |
| % | 여러 문자와 일치하는 패턴 | %학% | 철학, 학과 등 학이 포함된 문자열 |
| _ | 한 문자와 일치하는 패턴 | _학 | 학 앞에 임의의 한 문자가 존재하는 문자열 |
| [] | 1개 문자와 일치 | [0-9]% | 0-9 사이 숫자로 시작하는 문자열 |
| [^] | 1개 문자와 불일치 | [^0-9]% | 0-9 사이 숫자로 시작하지 않는 문자열 |
NULL
- NULL+숫자 연산의 결과는 NULL
- 집계함수 계산 시 NULL이 포함된 행은 집계에서 빠짐
- 해당되는 행이 하나도 없을 경우 SUM, AVG 함수의 결과는 NULL이 되며, COUNT 함수의 결과는 0
제약조건
- 테이블 레벨의 특정한 규칙을 말한다
- 예상치 못한 데이터의 손실이나 일관성을 어기는 데이터의 추가, 변경 등을 예방한다
다중 조건(CASE)
- 조회된 결과에서 중복된 데이터 제외하고 출력
- CASE는 내장함수는 아니며 연산자로 분류됨
- WHERE와 다른 점: WHERE는 결과를 얻기 위함 / CASE는 결과를 필터링하기 위함
SELECT
CUSTID,
SUM(SALEPRICE) AS '총구매액',
CASE
WHEN (SALEPRICE >= 15000) THEN '최우수고객'
WHEN (SALEPRICE >= 10000) THEN '우수고객'
WHEN (SALEPRICE >= 5000) THEN '일반고객'
ELSE
END AS '고객등급'
FROM ORDERS
GROUP BY CUSTID;
조건 제어(IF)
- 조건에 따라 분기
- IF(조건, 수식1, 수식2): 조건이 참이면 수식1, 거짓이면 수식2
- IFNULL(수식1, 수식2): 수식1이 NULL이 아니면 수식1, NULL이면 수식2
SELECT IF (100 > 200, '참', '거짓');
산술연산자
- +, -, *, /, %
비교연산자
- =, >, <, <>, !=
- 참(1), 거짓(0) 값 반환
논리연산자
- AND, OR, NOT
- 참(1), 거짓(0) 값 반환
문자열 다루기
- CONCAT: 컬럼과 문자열, 문자열과 문자열을 결합
SELECT
CONCAT ('출판사: ', PUBLISHER)
FROM BOOK;
SELECT
CONCAT ('홍길동', '모험')

- CONCAT_WS: 구분자로 컬럼과 문자열, 문자열과 문자열을 결합
SELECT CONCAT_WS(':', username, phone) AS '전화' FROM customer;
SELECT GROUP_CONCAT(username, ":", phone) AS "전화" FROM customer;
- LENGTH, CHAR_LENGTH: 문자열 길이 함수
# 문자열 BYTE 길이
SELECT
LENGTH (문자열)
# 문자의 갯수
SELECT
CHAR_LENGTH (문자열)
>> 6
>> 2
- TRIM, LTRIM, RTRIM: 공백제거
-- TRIM() - 문자열 좌우 공백 제거
SELECT TRIM(' 안녕하세요 ');
-- LTRIM() – 좌측 공백 제거
SELECT LTRIM(' 안녕하세요 ');
-- RLTRIM 우측 공백 제거
SELECT RTRIM(' 안녕하세요 ');
-- 문자열 좌측 문자 제거 (LEADING)
SELECT TRIM(LEADING '안' FROM '안녕하세요안');
-- 문자열 우측 문자 제거 (TRAILING)
SELECT TRIM(TRAILING '요' FROM '요안녕하세요');
>> 녕하세요안
>> 요안녕하세
- SUBSTRING, MID, LEFT, RIGHT: 문자열 추출
- 인덱스
| 안 | 녕 | 하 | 세 | 요 |
| 1 | 2 | 3 | 4 | 5 |
# 2번 인덱스부터 3개
SELECT SUBSTRING('안녕하세요', 2, 3);
# /로 구분하고 3번 인덱스까지
SELECT SUBSTRING_INDEX('안/녕/하/세/요', '/', 3);
SELECT LEFT('안녕하세요', 3);
SELECT RIGHT('안녕하세요', 3);
>> 녕하세
>> 안/녕/하
>> 안녕하
>> 하세요
날짜 자료형 다루기
- DATE_ADD, DATE_SUB: 기준날짜로부터 더하기, 빼기
SELECT DATE_ADD('2021-8-31', INTERVAL 5 DAY),
SELECT DATE_SUB('2021-8-31', INTERVAL 1 MONTH);
- DATEDIFF: 날짜1 - 날짜2
SELECT DATEDIFF('2021-8-31', '2022-8-31')
- DATE_FORMAT: 날짜 형식
SELECT DATE_FORMAT('2021-8-31', '%Y-%m-%d')
서브쿼리
- 상관 부속쿼리: 상위 부속쿼리의 튜플을 이용하여 하위 부속쿼리를 계산함
- 즉 상위 부속쿼리와 하위 부속쿼리가 독립적이지 않고 서로 연관을 맺고 있음
SELECT b1.BOOKNAME
FROM BOOK AS b1
WHERE b1.PRICE > (SELECT AVG(b2.PRICE)
FROM BOOK AS b2
WHERE b2.PUBLISHER = b1.PUBLISHER)- 인라인 뷰: FROM 절 안에 쓴 서브쿼리는 뷰처럼 취급함
GROUP BY
- COUNT
SELECT COUNT(*), COUNT(price)
FROM Orders;
COUNT(*) // NULL 포함
COUNT(PRICE) // NULL 미포함- HAVING: 그룹바이에 선택한 컬럼의 조건을 HAVING절에 지시
- HAVING 절 검색 조건에는 집계함수 사용
SELECT
code,
NAME,
min(price)
FROM product
GROUP BY name
HAVING min(price) < (select avg(price)
from product);JOIN
- INNER JOIN: 기본
- (LEFT, RIGHT, FULL) OUTER JOIN
- CROSS JOIN
집합 연산자
- 집합 연산자: 두 개의 SELECT 문의 결과에 대해 합, 교, 차집합을 구하는 연산자
- UNION(합집합)
# 거주지가 대한민국인 고객과
# 도서를 주문한 고객 가져오기
SELECT NAME
FROM CUSTOMER
WHERE ADDRESS LIKE '대한민국%'
UNION
SELECT NAME
FROM CUSTOEMR
WHERE CUSTID IN (SELECT CUSTID
FROM ORDERS)- NOT IN(차집합)
# 거주지가 대한민국인 고객 중
# 도서를 주문한 고객 제외하기
SELECT NANME
FROM CUSTOMER
WHERE ADDRESS LIKE '대한민국%' AND
NAME NOT IN (SELECT NAME
FROM CUSTOEMR
WHERE CUSTID IN (SELECT CUSTID
FROM ORDERS))- IN(교집합)
# 거주지가 대한민국이면서
# 도서를 주문한 고객 가져오기
SELECT NAME
FROM CUSTOMER
WHERE ADDRESS LIKE '대한민국%' AND
NAME IN (SELECT NAME
FROM CUSTOEMR
WHERE CUSTID IN (SELECT CUSTID FROM ORDERS))VIEW
- 하나 이상의 테이블을 결합하여 만든 가상의 테이블
- 기존 테이블 변경없이 새로운 데이터 구조를 사용할 수 있음
- 독립적인 인덱스 생성이 어려움
- 뷰의 속성 변경 불가(ALTER VIEW (x))
CREATE VIEW V_ORDERS
AS SELECT
O.ORDERID,
C.CUSTID,
C.USERNAME,
B.BOOKID,
O.SALEPRICE,
O.ORDERDATE
FROM CUSTOMER AS C
JOIN ORDERS AS O
JOIN BOOK AS B
ON C.CUSTID = O.CUSTID AND B.BOOKID = O.BOOKID
SELECT * FROM V_ORDERS;
집계함수
- WEEKOFYEAR, YEARWEEK, WEEK: 주 범위를 반환(0~53)
- DAYOFFYEAR: 일 년을 기준으로 날짜 수
/* 날짜 집계함수 */
-- WEEKOFYEAR
SELECT WEEKOFYEAR('2021-01-01'); -- 53 (2020년의 53주에 해당)
SELECT WEEKOFYEAR('2021-01-05'); -- 1 (2021년의 1주에 해당)
SELECT WEEKOFYEAR('2021-02-01'); -- 5 (2021년의 5주에 해당)
SELECT WEEKOFYEAR('2021-12-31'); -- 52 (2021년의 52주에 해당)
-- DAYOFFYEAR
SELECT DAYOFYEAR("2021-01-01"); -- 1
SELECT DAYOFYEAR("2021-06-15"); -- 166
SELECT DAYOFYEAR("2021-12-31"); -- 365
기본통계
기술통계
- 갯수, 최대값, 최솟값, 중간값
- 합, 평균
- RANK대표값
고객별 전체 주문횟수, 합계, 평균, 최소/최대 구매액
SELECT
C.USERNAME 이름,
COUNT(*) 주문량,
FORMAT(SUM(SALEPRICE),0) 합계,
FORMAT(AVG(SALEPRICE), 1) 평균,
MAX(SALEPRICE) 최대,
MIN(SALEPRICE) 최소
FROM ORDERS O LEFT JOIN CUSTOMER C ON O.CUSTID = C.CUSTID GROUP BY 이름;주문 금액의 합계, 평균, 최소, 최대, 분산, 표준편차
SELECT
SUM(SALEPRICE) 합계,
FORMAT(AVG(SALEPRICE), 1) 평균,
MAX(SALEPRICE) 최대,
MIN(SALEPRICE) 최소,
FORMAT(VARIANCE(SALEPRICE),1) 분산,
FORMAT(STD(SALEPRICE),1) 표준편차 FROM ORDERS;사분위수
- GROUP_CONCAT 함수로 데이터를 합쳐서 분위수에 해당하는 수치를 구해 SUBSTRING_INDEX 함수로 데이터를 추출하는 방법이다.
- 합쳐지는 데이터가 많을 경우 꼭 SET GROUP_CONCAT_MAX_LEN = 10485760; 와 같은 설정이 필요함
가격 개수를 이용한 사분위수
-- 1단계: 컬럼 결과를 한 줄로 결합
SELECT
publisher,
GROUP_CONCAT(bookname SEPARATOR ':')
FROM book
GROUP BY publisher;
-- 2단계: 모든 가격을 결합한다.
SELECT
GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ',')
FROM Orders;
-- 3단계: 전체 레코드 수를 25%~100% 까지 계산해 본다.
SELECT
25/100 * COUNT(saleprice) + 1 AS '25%',
50/100 * COUNT(saleprice) + 1 AS '50%',
70/100 * COUNT(saleprice) + 1 AS '75%',
MAX(saleprice) AS 'MAX'
FROM Orders;
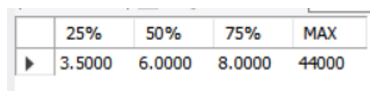
-- 4단계:
-- substring_index(str, delim, count)
-- 문자열 str 을 delim 로 구분해서 배열로 만든 후 count 만큼만 보여준다.
-- count 가 양수이면 왼쪽에서 count 수만큼 보여주고 음수이면 오른쪽에서 count 수 만큼 보여준다.
select substring_index('www.mysql.com', '.', 1); -- 'www'
select substring_index('www.mysql.com', '.', -1); -- 'com'
-- 5단계: FINAL
-- 합쳐지는 데이터가 많을 경우 꼭 SET GROUP_CONCAT_MAX_LEN = 10485760; 와 같은 설정이 필요함
-- SET GROUP_CONCAT_MAX_LEN = 10485760;
SELECT MIN(saleprice) AS 'MIN',
SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 25/100 * COUNT(*) + 1), ',', -1) AS `25%`,
SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 50/100 * COUNT(*) + 1), ',', -1) AS `50%`,
AVG(saleprice) AS 'MEAN',
SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 75/100 * COUNT(*) + 1), ',', -1) AS `75%`,
MAX(saleprice) AS 'MAX'
FROM Orders;

- 전체 가격 범위는 판매가를 합산 가격으로 계산해 사분위 범위
SELECT MIN(saleprice) AS 'MIN',
FORMAT(25/100 * **SUM(saleprice)**, 1) AS '25%',
FORMAT(50/100 * SUM(saleprice), 1) AS '50%',
FORMAT(AVG(saleprice),1 ) AS 'MEAN',
FORMAT(70/100 * SUM(saleprice), 1) AS '75%',
MAX(saleprice) AS 'MAX'
FROM Orders;
순위
- RANK: 1,2,2,4,5
- DENES_RANK: 1,2,2,3,4
- ROW_NUMBER: 1,2,3,4,5
소계
- ROLLUP
SELECT
DEPTNO,
JOB,
SUM(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB);
'유데미 스타터스 데이터 분석' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 6주차 학습 일지 (1) | 2023.03.19 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 5주차 학습 일지 (0) | 2023.03.12 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(3) (0) | 2023.03.10 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(2) (0) | 2023.03.09 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(1) (0) | 2023.03.05 |

댓글