2022.03.20 ~ 2022.03.24

7주차는 다양한 집계를 할 수 있는 Primary 함수와 LOD를 중심으로 태블로 프로젝트를 진행했다.
매개변수를 설정하는 것은 조금 익숙해졌지만 datediff와 대상날짜, 날짜 매개변수를 함께 사용하여 조건을 부여하는 것, 시작일과 종료일을 각각 조정하여 조회기간을 설정할 수 있도록 매개변수를 설정하는 것은 어려웠던 부분이었다.
그리고 역시 메인은 LOD로, 개념을 이해하기 위해서 백단에서 어떤 연산이 이루어지는지 순차적으로 접근해야 했고 그나마 쉽다고 여겼던 LOD fixed 연산도 실제 사용 시에는 헷갈리는 부분이 있었다.(가령 VLOD에 존재하는 차원도 fixed 해야 하는지? 결론은 안전하게 접근한다면 이미 존재하는 차원도 fixed 할 수 있다!)
그래서 이번 주 학습일지에서는 LOD 개념과 함께 프로젝트를 복기하면서 사용했던 매개변수와 LOD를 복습하려 한다.
목차
태블로 LOD 뽀개기
프로젝트 1: 미국 대학 기부금 모금 현황
프로젝트 2: SuperStore Sales Tracking Dashboard
태블로 LOD 뽀개기

👉 furniture 카테고리는 497, 530, 95, 638 4개의 서브 카테고리 평균 값으로 구성되어 있다
Include 개념
✅ include는 평균의 평균이다
{include [sub-category] : avg([Sales])}
👉 서브 카테고리를 포함하는 레벨에서 avg([sales]) 계산이 먼저 이루어진다
👉 그 결과를 가지고 카테고리를 기준으로 다시 계산이 이루어진다
include LOD는 태생적으로 어떤 새로운 차원을 포함하고 있기 때문에
include LOD에서 만든 결과는 VLOD보다 뎁스가 깊을 수 밖에 없다
더 깊은 레벨(서브 카테고리)에서 계산된 결과를 그보다 얕은 레벨(카테고리)에서 표현해야 하기 때문에
계산이 다시 이루어질 수 밖에 없다
Include 계산 순서
(첫 번째 계산) include LOD에 명시된 차원을 포함하여 집계가 이루어진다
(두 번째 계산) VLOD의 차원에 맞춰 표현하기 위해 첫 번째 계산 결과를 재집계 한다
참고: 태블로 레벨UP(VizLab)
Include 작동 원리
1) 계산된 필드 생성

👉 서브 카테고리를 기준으로 평균을 구한다
결과

👉 좌: 전체 데이터에서 카테고리별 평균 | 우: 서브 카테고리 평균의 평균
👉 즉 (497 + 530 + 95 + 638) / 4 = 440(439.9)
Include 응용
도시별 평균 매출의 차이가 가장 큰 주 구하기
1) 계산된 필드 생성

👉 도시를 포함하는 레벨에서 avg([sales]) 계산이 먼저 이루어진다
2) 최대값, 최소값

👉 그 결과를 가지고 주를 기준으로 다시 최댓값, 최솟값 계산이 이루어진다
- 한 그래프에 두 측정값 표시

+) 편차 시각화
- 측정값 복사, 이중축 적용, 라인 스타일 적용

- 경로 표시

3) 편차 큰 순서로 정렬
- 계산된 필드 생성

- 계산된 필드 기준으로 state/province 내림차순 정렬

결과

exclude 개념
✅ exclude는 복제다
{exclude [sub-category] : avg([Sales])}
👉 서브 카테고리를 제외하는 레벨에서 avg([sales]) 계산이 먼저 이루어진다
👉 그 결과를 가지고 서브 카테고리를 기준으로 다시 전시가 이루어진다
exclude 계산 순서
(첫 번째 계산) exclude LOD에 명시된 차원을 제외한 후 집계가 이루어진다
(두 번째 계산) VLOD의 차원에 맞춰 표현하기 위해 첫 번째 계산 결과를 복제한다
단, exclude가 효과적으로 작동하기 위해서는 exclude LOD에서 선언한 차원이 VLOD에 포함되어 있어야 한다
참고: 태블로 레벨UP(VizLab)
exclude 작동 원리
1) 계산된 필드 생성

👉 서브 카테고리의 상위 평균을 구한다
결과

👉 좌: 전체 데이터에서 서브 카테고리별 평균 | 우: 서브 카테고리의 상위 평균(전체 데이터에서 카테고리별 평균
exclude 응용
서브 카테고리별 차이 구하기
1) 계산된 필드 생성

👉 서브 카테고리 'Binders'의 sales 연산
결과

2) 계산된 필드 생성

👉 서브 카테고리를 제외하는 카테고리 레벨에서 sum([sum([Binders])]) 계산이 먼저 이루어진다
결과

👉 서브 카테고리보다 상위 범주인 카테고리가 VLOD에 존재하지 않는 상태로, 모든 서브 카테고리가 같은 값을 가짐
3) 계산된 필드 생성

결과

도시별 소속 주에 대한 수익 기여도 구하기
1) 계산된 필드 생성

👉 도시를 제외하는 주 레벨에서 sum([profit]) 계산이 먼저 이루어진다
2) 계산된 필드 생성

+) 크기: 절댓값 적용
결과

👉 기여 정도를 크기로 식별, 기여도 수치를 색상으로 식별
프로젝트 1: 미국 대학 기부금 모금 현황
사용 데이터
GiftRecords
GraduationYear
- Allocation
- Subcategory
- City
- College
- Gift
- Allocation
- Gift Amount
- Gift Date
- Major
- Prospect ID
- State
- Prospect ID
- Year of Graduation
결과

1. 일자별 기부금액(원)
1) 매개변수 생성(날짜)

👉 gift date 기준 날짜 매개변수 생성
2) 계산된 필드 생성(MTD, YTD)


3) 매개변수 생성(MTD, YTD)

4) 계산된 필드 생성

결과

2. MTD, YTD 집계값
1) 계산된 필드 생성

결과

3. MoM, YoY
1) 계산된 필드 생성
- MoM, YoY


👉 조회월 기준으로 구하려면 datediff = 0
- 계산 5

👉 매개변수(MTD, YTD)에 따라 MoM, YoY 값 출력되도록 설정
- 계산 6

👉 "MoM(%)", "YoY(%)" 문자열 출력
+) MoM, YoY 매개변수 별도 생성할 경우


결과

4. 기부금액 / 기부금액 비율
1) 매개변수 생성(기부금액(원), 기부금액(%))

2) 계산된 필드 생성

👉 기부금액(원) 선택 시 MTD, YTD 집계값 | 기부금액(%) 선택 시 전체 기부금액에서 차지하는 비율
결과

프로젝트 2: SuperStore Sales Tracking Dashboard
사용 데이터
SuperStore
- 고유 ID
- 주문 Id
- 주문 날짜
- 배송 날짜
- 배송 형태
- 고객번호
- 고객 이름
- 세그먼트
- 국가
- 지역
- 시도
- 시군구
- 제품 코드
- 범주
- 하위 범주
- 매출
- 수량
- 수익
- 할인율
결과

1. 지역별 판매량 대비 수익율
1) 매개변수 생성(시작일, 종료일)


👉 Order date 기준 {년도-분기} 매개변수 생성
2) 계산된 필드 생성


👉 시작날짜 조건: 시작일/종료일 매개변수와 Order date의 분기차이가 0보다 작거나 같음 | 끝날짜 조건: 시작일/종료일 매개변수와 Order date의 분기차이가 0보다 크거나 같음

👉 날짜 조건에서 헷갈렸던 부분! datediff 의 연산순서가 시작-끝인 것으로 착각했는데 끝-시작 순으로 두 날짜의 차를 구하는 것이었다.
결과

2. 수익이 저조한 서브 카테고리
1) 필터 조건 수식 적용

✅ 서브 카테고리의 수익이 0 이상인 지역이 3개 이면서 서브 카테고리의 수익이 0 미만인 지역이 1개
SUM({ FIXED [Sub-Category],[Region]: IF SUM([Profit]) >= 0 THEN 1 END})= 3 AND
SUM({ FIXED [Sub-Category],[Region]: IF SUM([Profit]) < 0 THEN 1 END}) = 1
결과
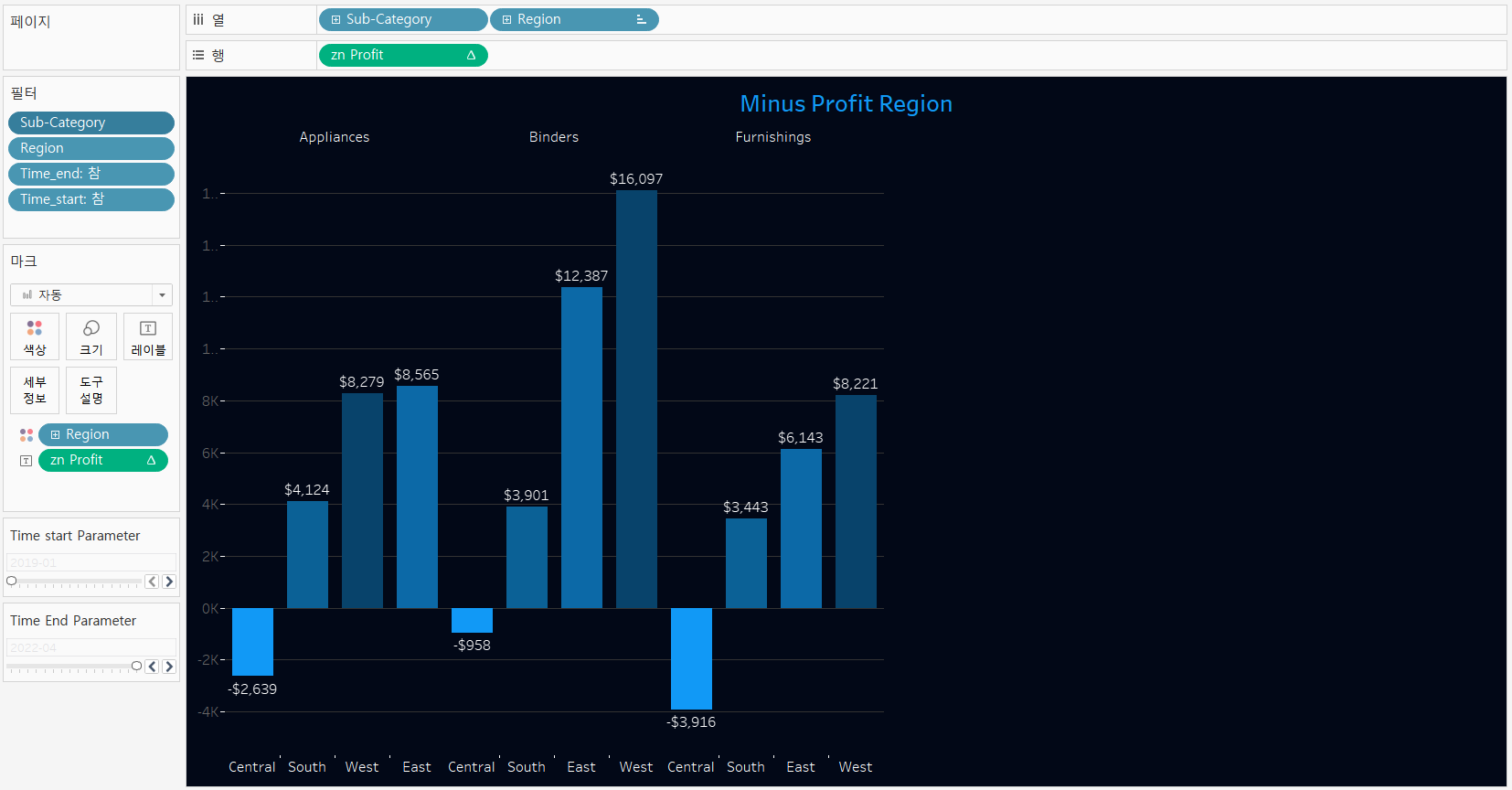
3. 지역별 수익율과 할인율
1) 계산된 필드 생성(할인율)

👉 지역별, 주별 할인율 평균
결과
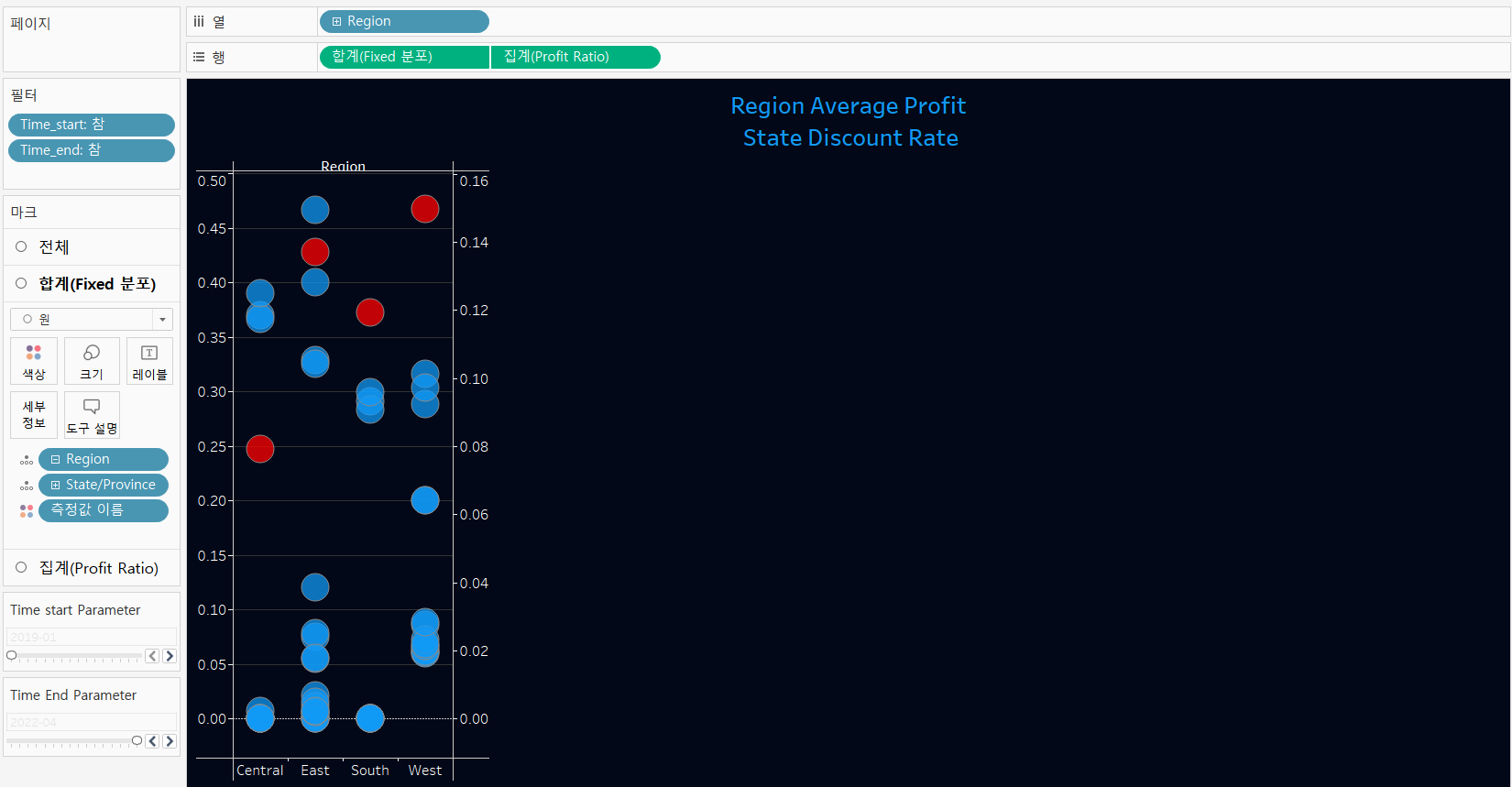
4. 수익이 저조한 서브 카테고리와 제조사의 수익과 할인율
1) 계산된 필드 생성(수익)

2) 계산된 필드 생성(할인율)

✅ Null 값을 0으로 처리하기
zn(lookup(계산식, 0))
결과

복습만 해도 벅찬 한 주였다. 지금까지 정말 많은 내용을 빠르게 배웠는데 다음 주에는 새롭게 배울 내용이 있을지 기대된다!!
>> 유데미 바로가기
>> STARTERS 취업 부트캠프 공식 블로그 보러가기
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터 분석 과정 학습 일지 리뷰로 작성되었습니다.
#유데미 #유데미코리아 #유데미큐레이션 #유데미부트캠프 #취업부트캠프 #스타터스부트캠프 #데이터시각화 #데이터분석 #데이터드리븐 #태블로
'유데미 스타터스 데이터 분석' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 9주차 학습 일지 (0) | 2023.04.09 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 8주차 학습 일지 (0) | 2023.04.02 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 6주차 학습 일지 (1) | 2023.03.19 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 5주차 학습 일지 (0) | 2023.03.12 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(4) (2) | 2023.03.10 |



댓글