2022.03.13 ~ 2022.03.17
6주차부터 우당탕탕 태블로 실습이 시작되었다. (벌써 반이나 지났다니!) 태블로 실습 첫 주 강의는 대시보드 기획과 기본 차트 생성을 중심으로 진행되었지만 실제 프로젝트 과제를 수행할 때는 훨씬 다양한 기능들을 복합적으로 사용했고, 그 결과 아래 이미지와 같은 상황이 자주 발생했다.

그래서 사용했던 기능들과 개념들을 하나씩 되짚어보고 만들었던 대시보드를 복습, 수정해보려 한다.
목차
태블로 그룹, 집합, 필터 뽀개기
프로젝트: 에어비앤비 객실&호스트 현황 분석 및 실적 개선 제안
태블로 그룹, 집합, 필터 뽀개기
먼저 이 3개의 개념을 확실하게 짚고 넘어간다.
- 그룹: group by의 그 group이다. 즉 하나의 그룹으로 묶이면 병합 집계된다는 뜻.
- 집합: In or Out, Yes or No와 같이 두 개의 범주로 구분할 때 쓰인다. 단 그룹처럼 병합 집계되지는 않는다.
- 필터: 조건에 해당되는 데이터만 걸러준다. where 절에 해당된다.
그룹 만들기
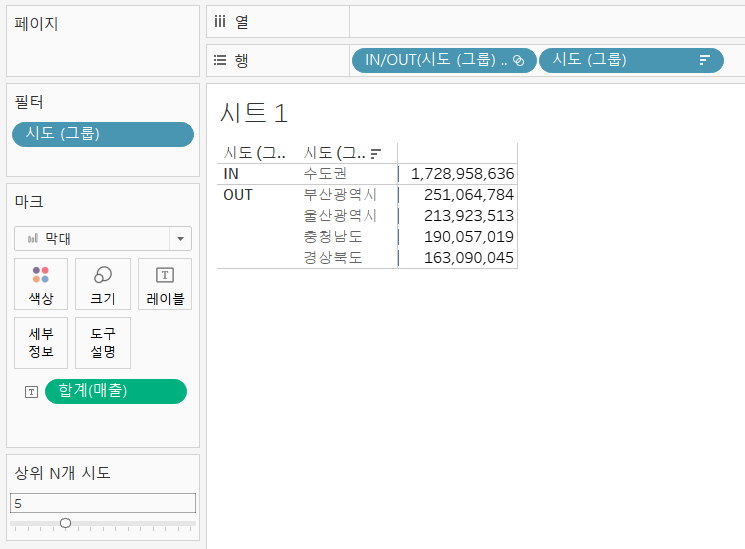
차원을 병합하여 하나의 측정값으로 확인할 수 있다. 경기도와 서울특별시, 인천광역시를 선택하여 '수도권'이라는 그룹으로 생성한다.
그룹 만들기 응용
그룹을 활용하여 수도권과 비수도권의 매출 합계를 비교하고자 한다. 여기서 중요 포인트는 집합이 아닌 그룹을 사용했다는 점이다. 수도권과 비수도권처럼 두 가지의 범주로 구분한다 라고 하면 집합(IN/OUT)이 먼저 떠오르는데 그룹을 사용해야만 하는 경우가 있다. (매출 합계라는 그룹별 집계 값을 비교해야 하기 때문인 이유도 있다)
우선 앞서 만들었던 그룹을 편집하여 '비수도권' 그룹을 생성한다.
행에는 매출-합계를, 색상 마크에는 그룹을 지정해준다. 두 그룹을 시각적으로 구분하기 위해서 상-하 형태의 차트로 수정이 필요하다.
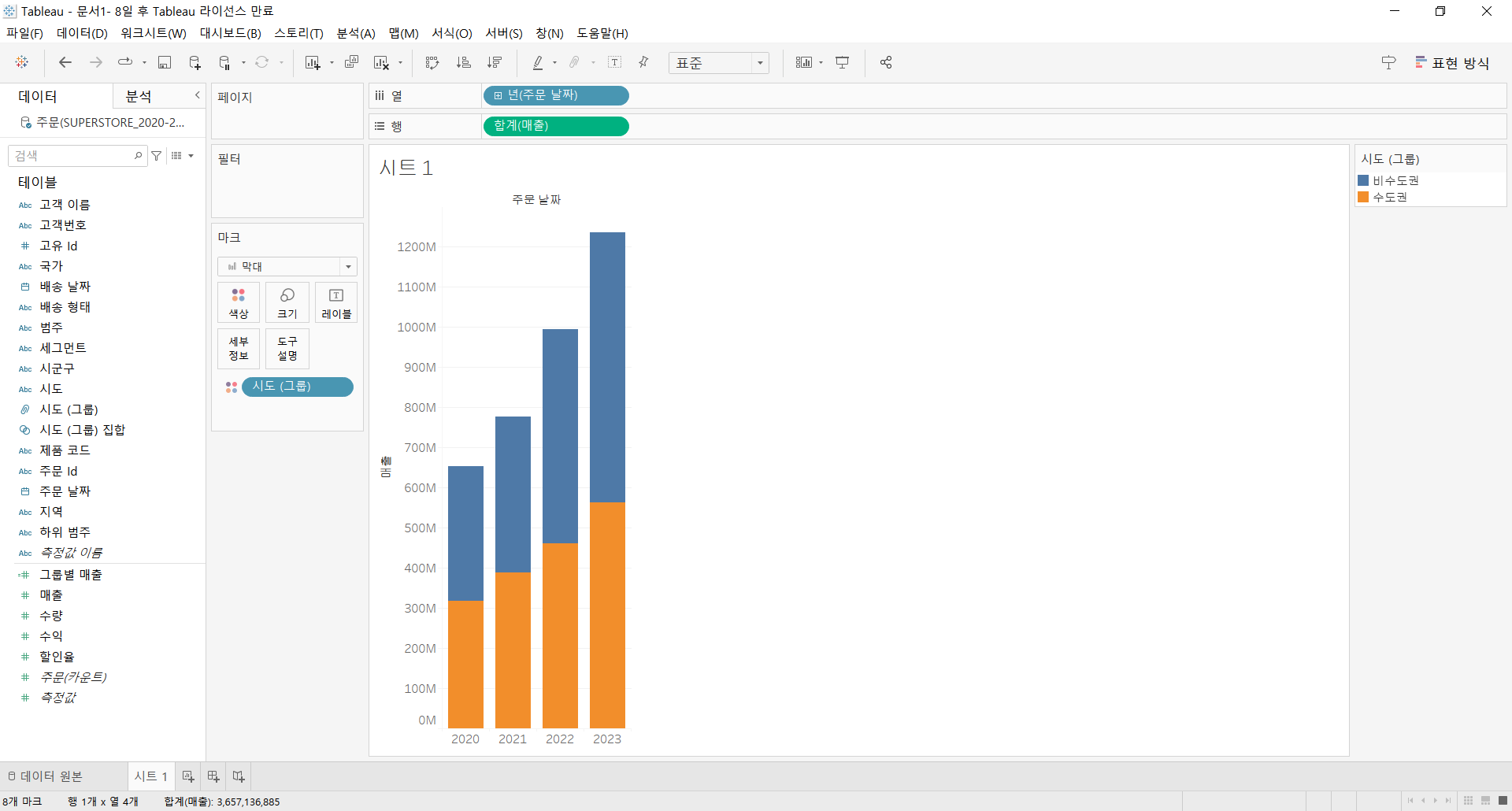
상-하 형태의 차트로 수정하기 위해서는 특정 그룹의 매출에 마이너스를 취해주는 조작이 필요하다. 여기서 집합이 아닌 그룹을 사용한 이유가 드러나는데, 계산된 필드에서 집합을 조건으로 사용할 수 없기 때문이다.
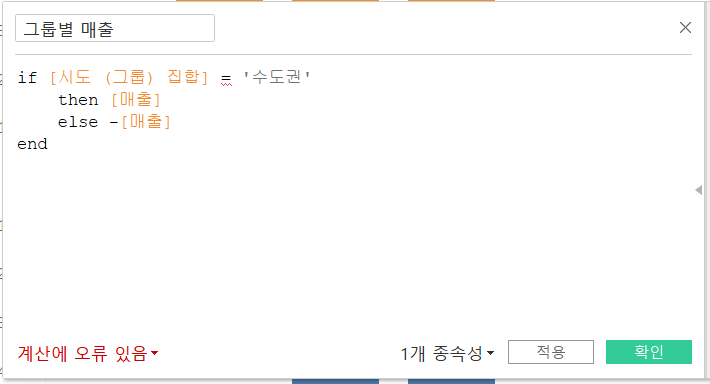
'값 부울과 값 문자열을 비교할 수 없습니다'라는 오류 메시지를 통해 집합은 IN/OUT, 즉 부울 값으로 범주를 구분한다는 것을 알 수 있다.
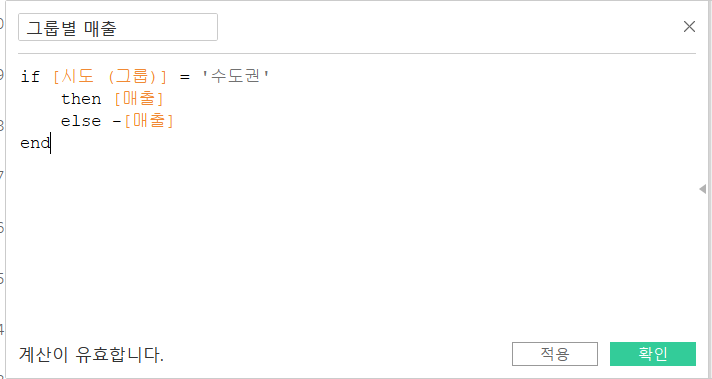
따라서 집합이 아닌 그룹으로 조건문을 완성한다.
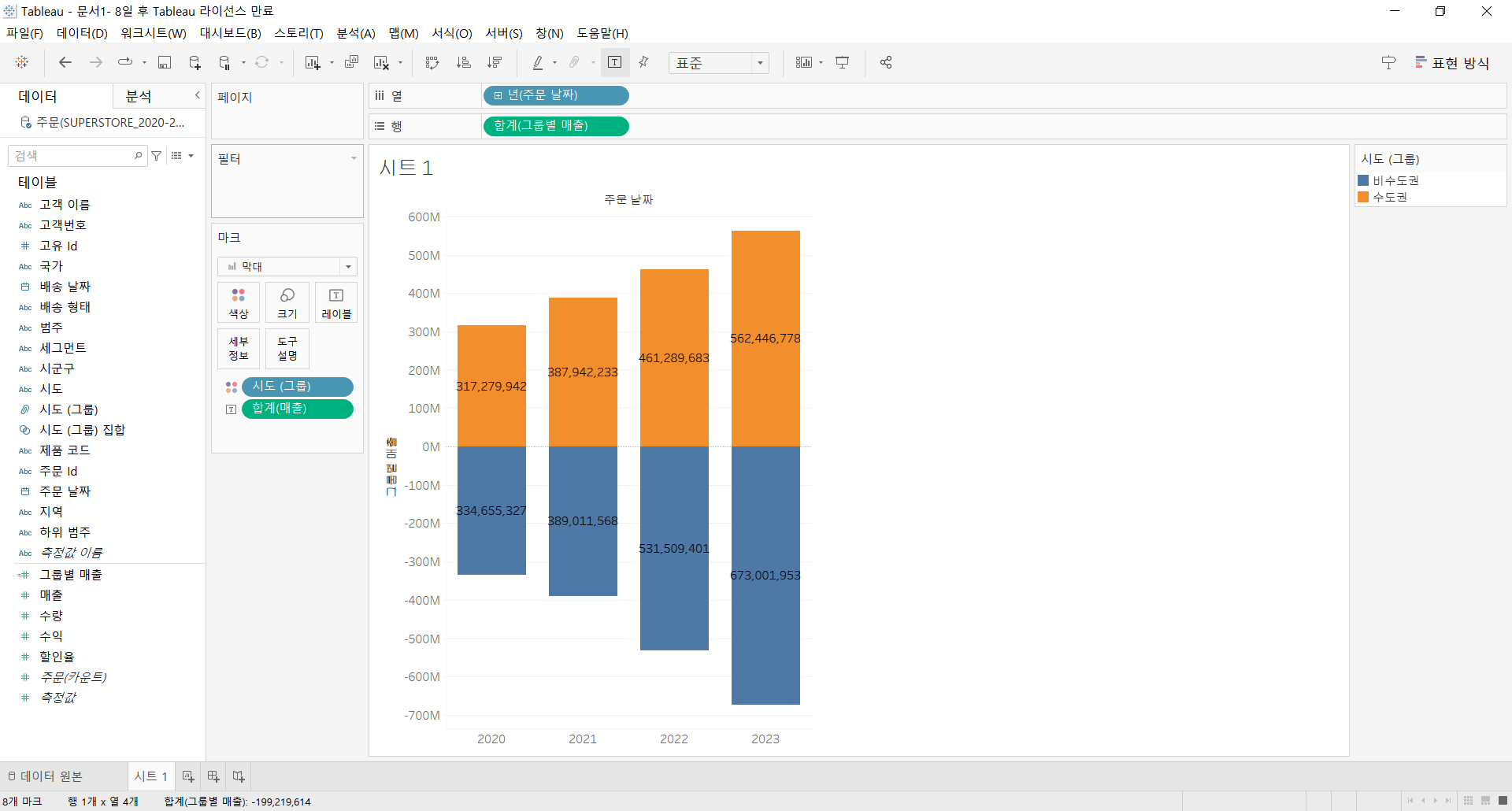
수도권과 비수도권 그룹의 매출 합계를 비교할 수 있는 상-하 형태의 차트가 완성되었다.
집합 만들기
한편 집합은 IN/OUT 두 가지 범주로 구분할 때 사용한다. 가령 '수도권' 그룹에 대해서 집합을 생성하면 IN으로, 선택하지 않은 나머지 지역들은 자동으로 OUT으로 구분된다.
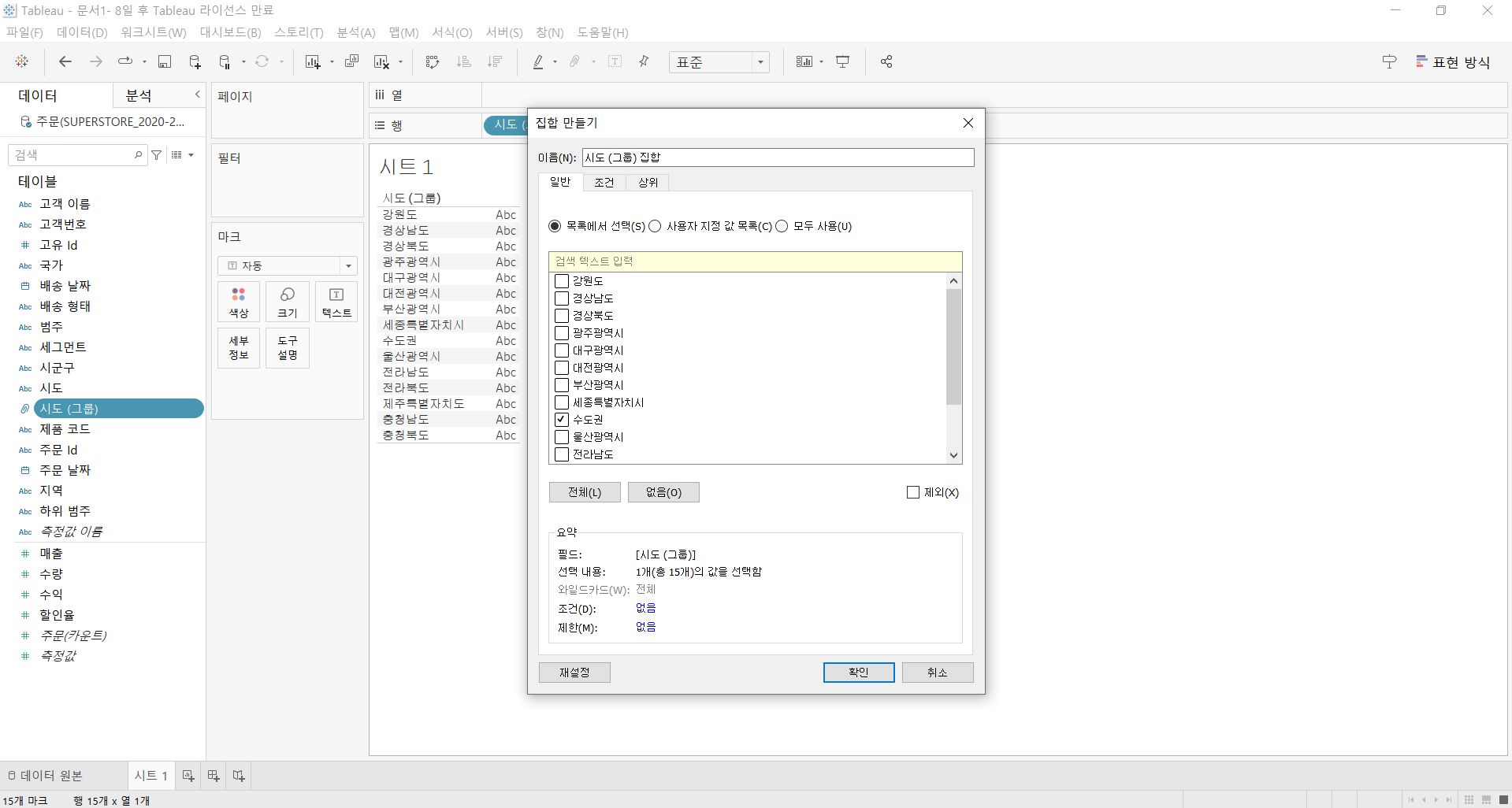
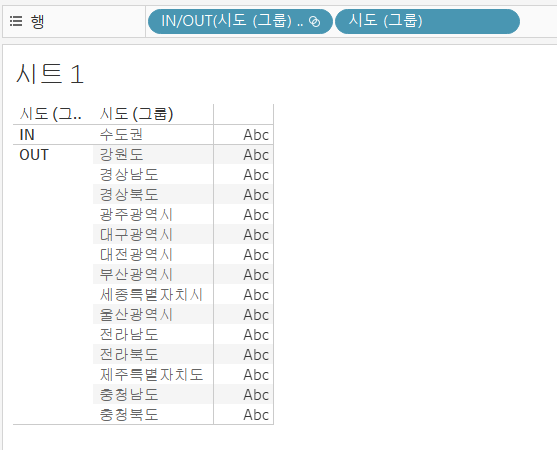
동적 집합 만들기
집합 항목을 직접 선택하는 대신 조건에 따라 IN/OUT 범주가 구분되도록 지정할 수 있다. 조건 탭에서 '매출 합계 1,000,000,000 이상' 조건을 부여하고 집합을 생성하면 조건에 해당되지 않는 지역들은 자동으로 OUT으로 구분된다.
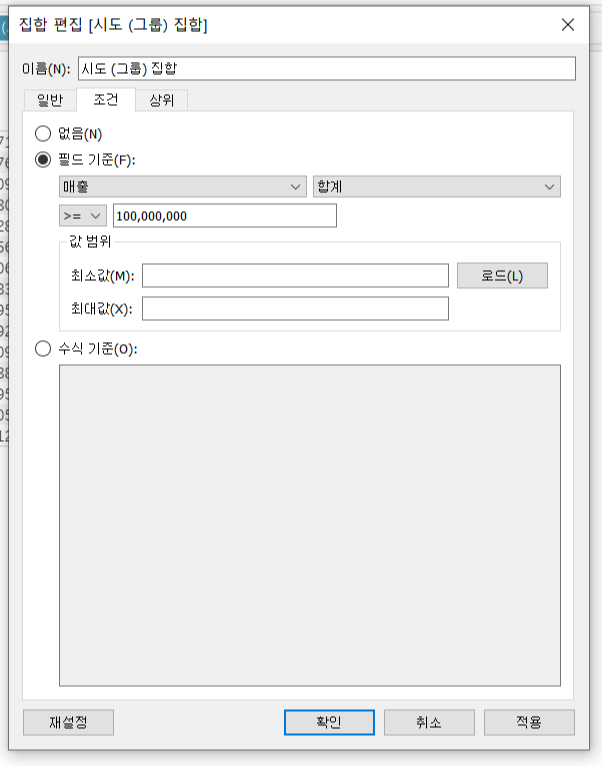
집합 만들기 응용
집합과 매개변수를 활용하여 매출 상위 N개의 시도를 구하고자 한다. 이 때 매개 변수를 사용하여 N의 크기를 조작할 수 있도록 하는 것이 포인트이다.
우선 수도권과 나머지 시도의 갯수가 총 15개이므로 1부터 15까지 범위의 매개변수를 생성한다.
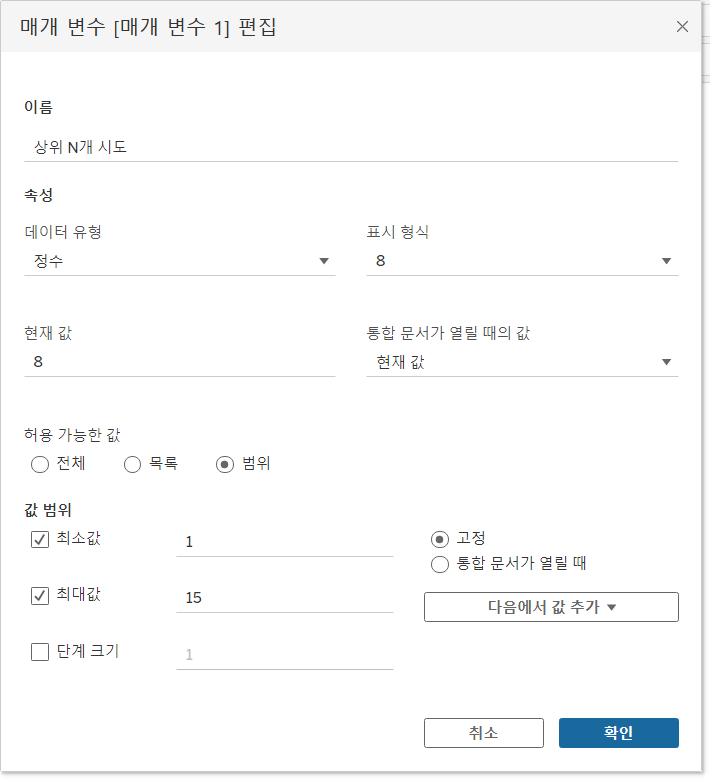
그 다음 집합의 조건 탭에서 '상위 N개 시도' 매개변수의 '매출 합계' 조건을 부여하고 집합을 생성하면 조건에 해당되지 않는 지역들은 자동으로 OUT으로 구분된다.
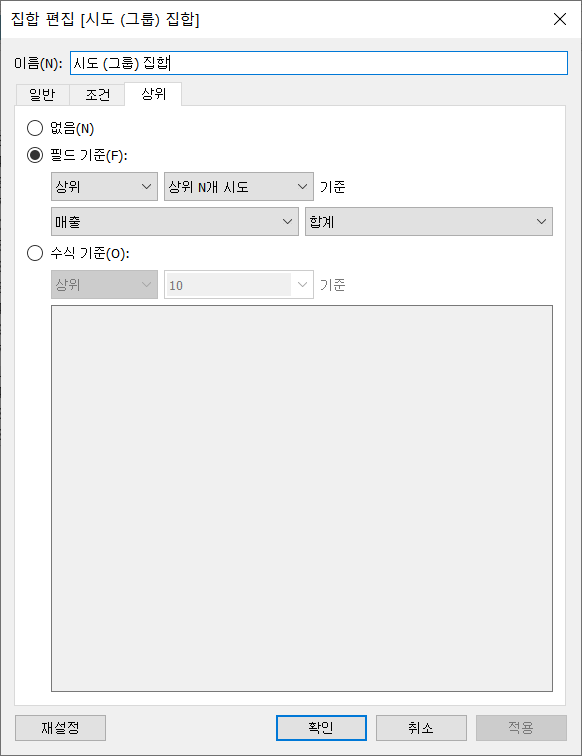
매개 변수의 값을 5로 조정하면 상위 5개의 시도가 IN 집합에 포함된 것을 확인할 수 있다.
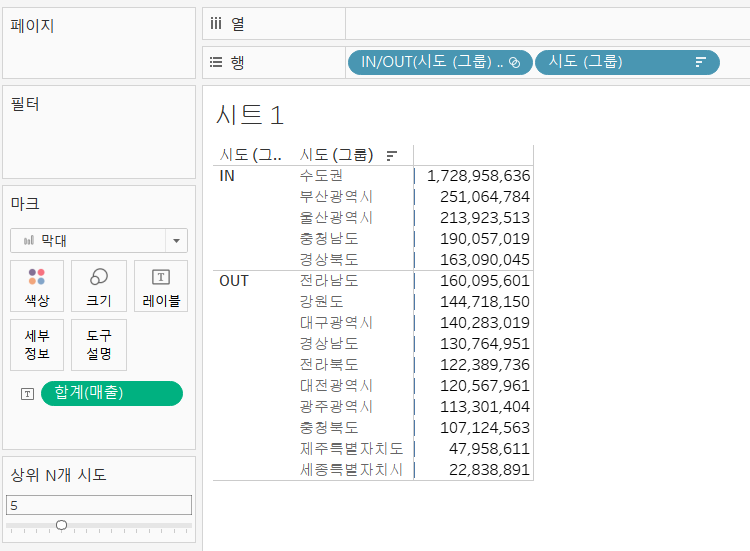
매출 상위 N개의 시도를 구한다 라고 하면 필터를 가장 먼저 떠올리게 되는데 위와 같이 집합과 매개변수를 활용한 이유가 있다. 가령 매출 필터의 경우 값의 범위를 지정하기 때문에 비율이나 등수를 기준으로 필터링하기 어렵다.
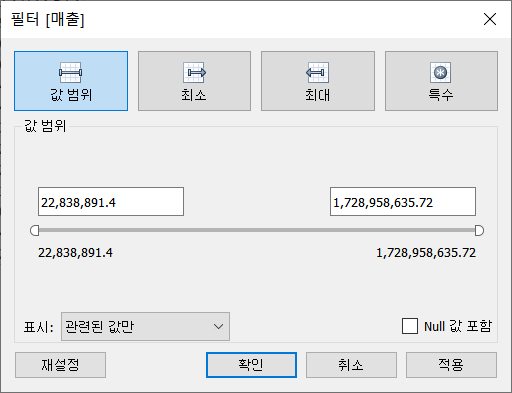
다만 시도(그룹)과 같은 범주형 데이터를 필터에 추가해서 필터의 조건에 매개변수를 지정하는 방법도 있다.
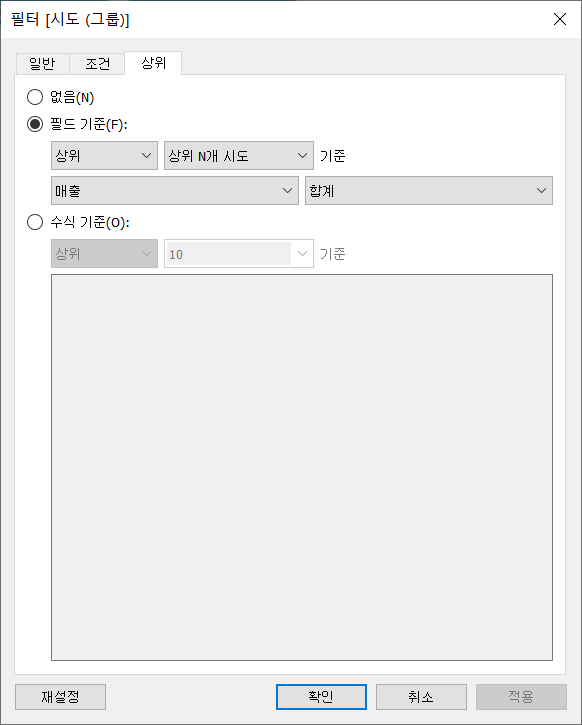
이렇게 필터에 매개변수를 지정하면 데이터 자체에서 필터링을 적용하는 것이라 집합과는 관계없이 상위 N개의 데이터만 가져온다.(집합에는 '수도권'을 지정한 상태이므로 IN 집합에는 수도권만이 포함되어 있다)
프로젝트: 에어비앤비 객실&호스트 현황 분석 및 실적 개선 제안
사용 데이터
에어비앤비 객실 데이터
- Host Id
- Host Since
- Name
- Neighbourhood
- Property
- Type
- Review Scores Rating (bin)
- Room Type
- Zipcode
- Beds
- Number of Records
- Number Of Reviews
- Price
- Review Scores Rating
1) 우수 객실 선정하기
우수 객실 리스트를 구할 때 Host Room Name 집합을 필터로 걸었고 해당 집합에는 상위 N개의 Host Room Name을 가져오는 score leaders 라는 매개변수가 걸려있었다.
수정 전
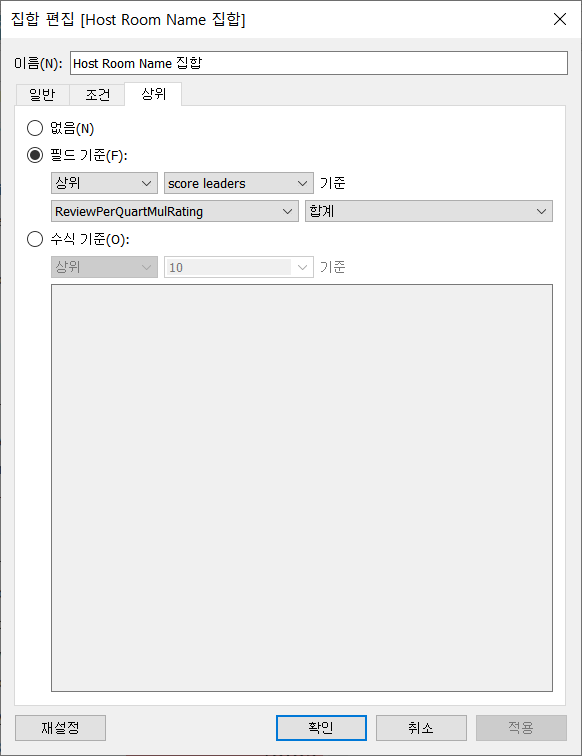
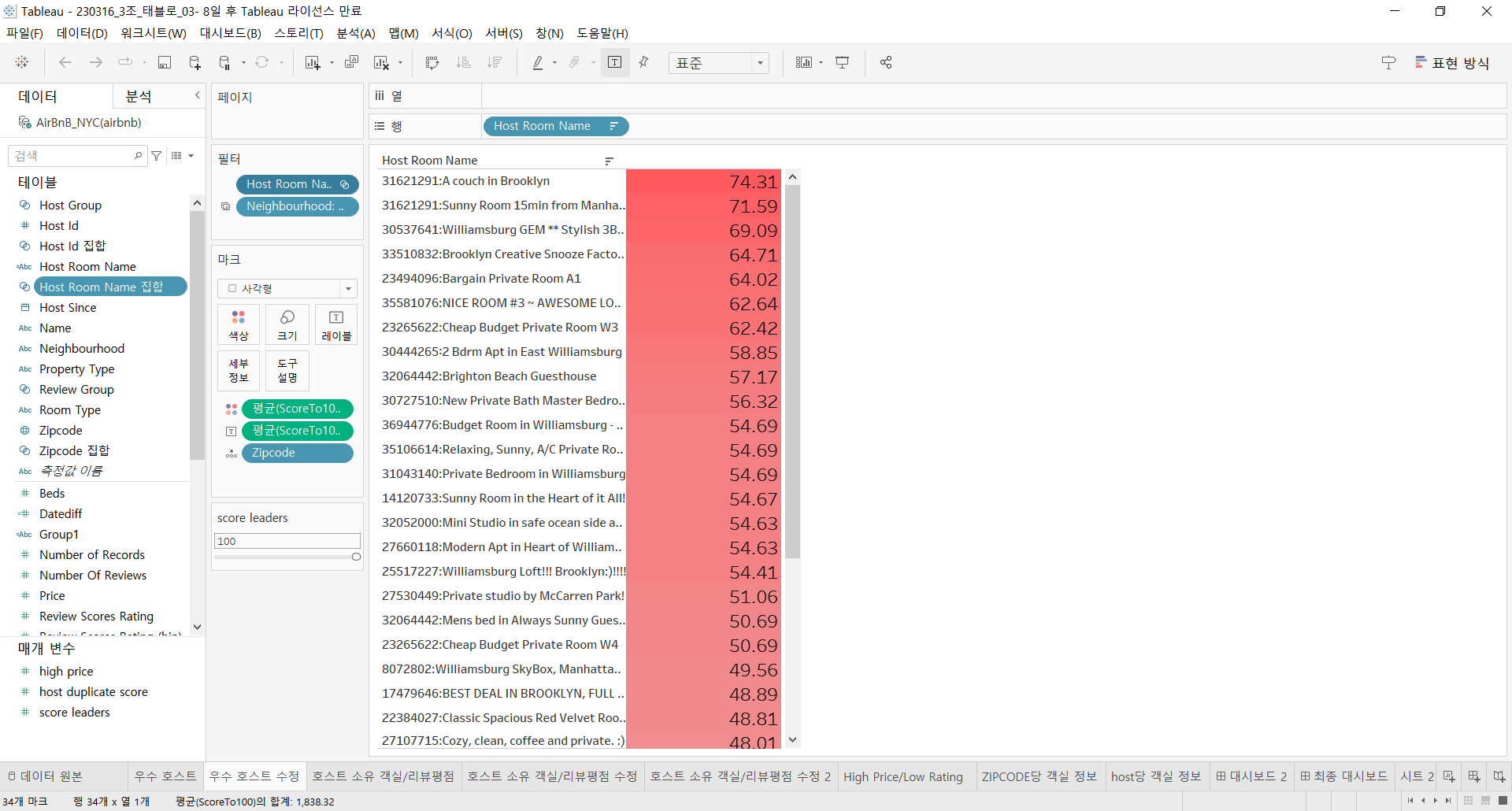
다만 상위 N개의 데이터를 확인하기 위한 목적에서는 IN/OUT 두 가지 범주를 구분할 필요가 없기 때문에 굳이 Host Room Name 집합을 생성하여 필터로 활용할 이유가 없다.
따라서 앞서 집합 만들기 응용에서 발견한 것과 같이 범주형 데이터인 Host Room Name을 필터에 추가해서 필터 상위 조건에 score leaders 매개변수를 지정하는 방식으로 수정하였다.
수정 후
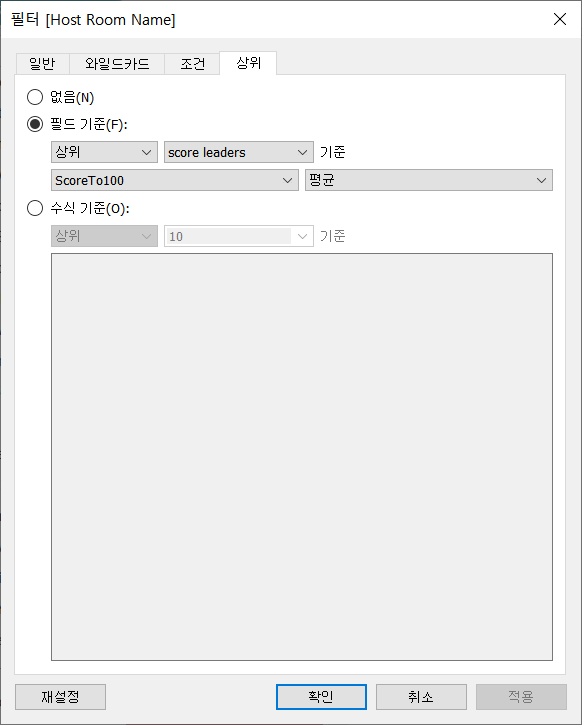
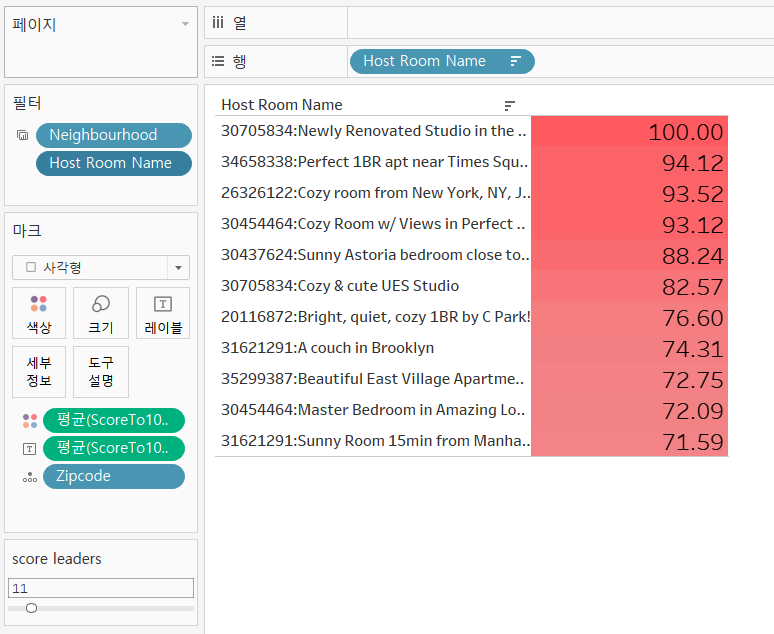
결과는 수정 전과 동일하게 score leaders에 따라 상위 N개의 Host Room Name이 출력되는 것을 확인할 수 있다.
2) 멀티 호스트의 리뷰 평점
멀티 호스트 별 리뷰 평점을 구할 때는 Host id를 필터로 걸었고 해당 필터에는 host duplicate score라는 매개변수가 걸려있었다. 이 차트는 별도로 수정이 필요하지 않았다.
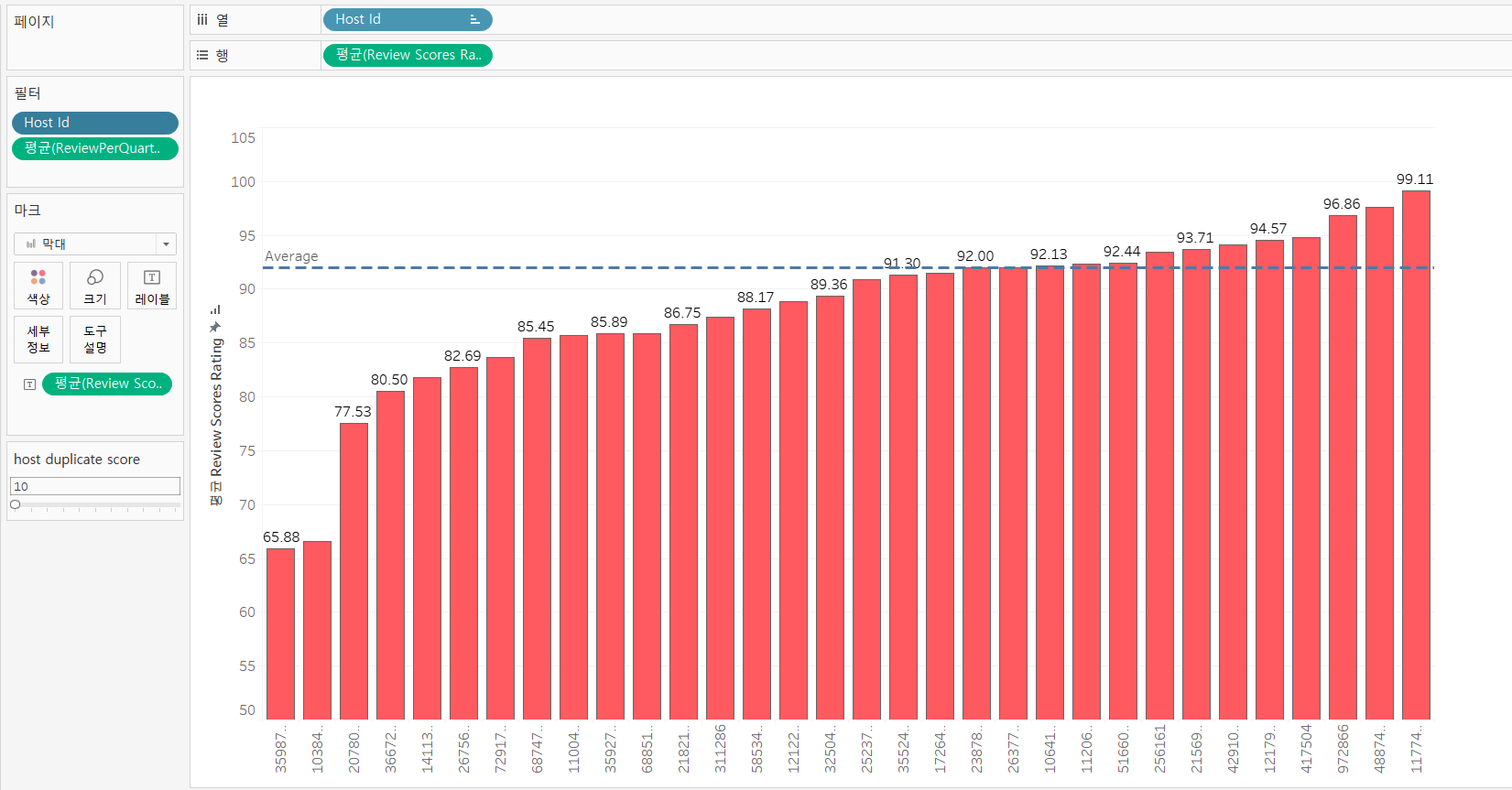

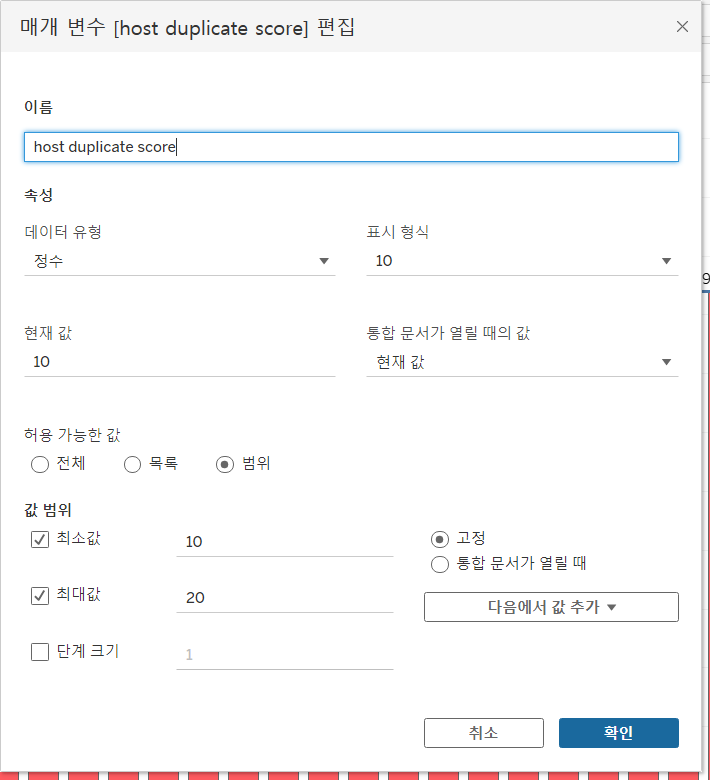
Host id 역시 Host room name과 마찬가지로 범주형 데이터이기 때문에 Host id 필터의 조건에 매개변수를 지정하여 데이터 자체에서 필터링을 적용한 방식이다. 단 이 경우는 상위 N개를 가져오는 것이 아니라 count(Host id), 즉 호스트가 보유한 객실의 갯수에 대해 조건(매개변수 host duplicate score)을 부여한 것이기 때문에 필터 수식 조건을 부여하였다.
3) High Price/Low Rating
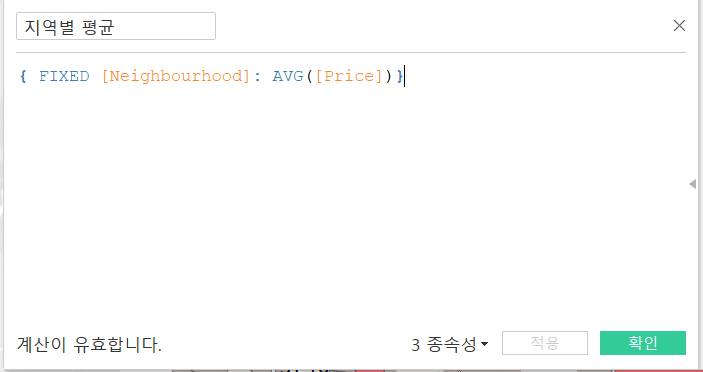
(색상으로 표시한) 지역별 평균 가격 대비 객실 가격을 구할 때는 먼저 LOD를 사용해서 지역별 평균을 구하고 Zipcode의 집합을 생성하여 지역별 평균보다 높은 경우 IN 집합에 포함되도록 했다.
수정 전
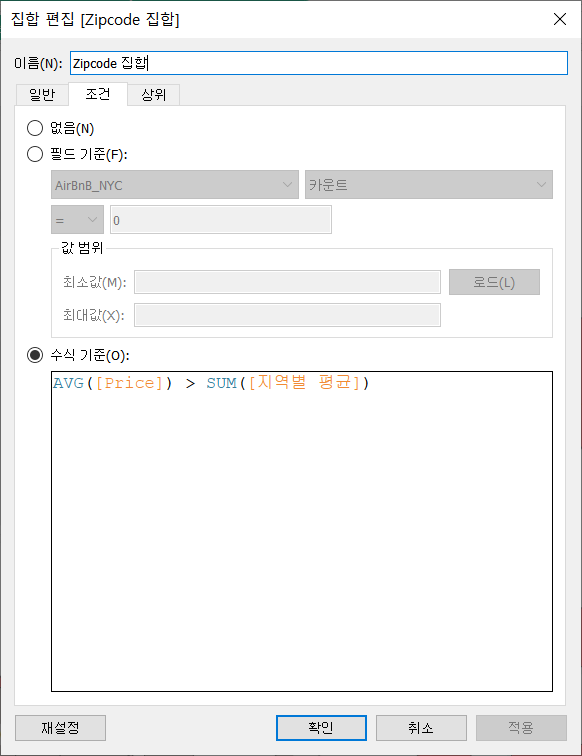
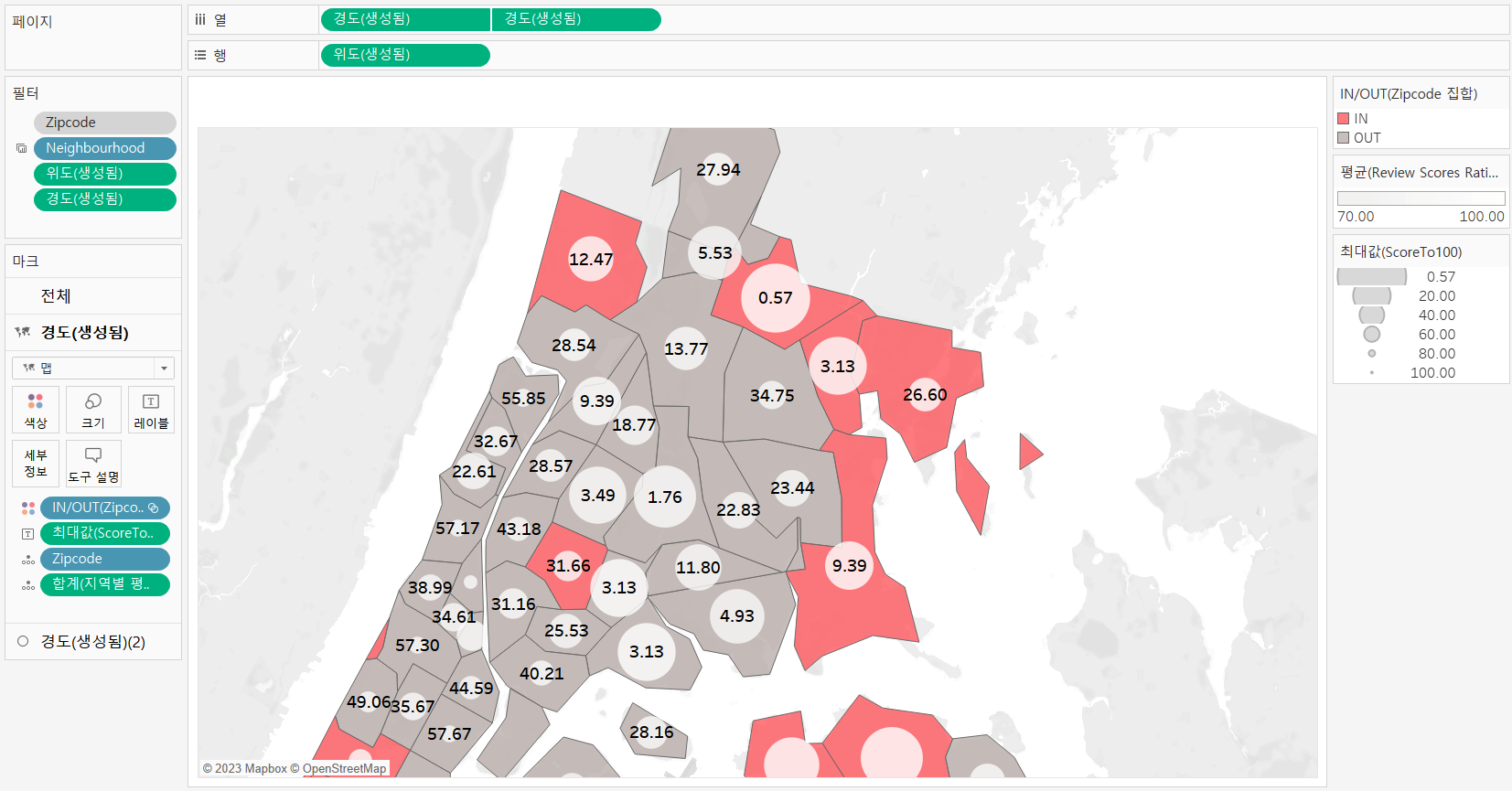
다만 원으로 표시한 평점 부분에서 원의 크기와 색상이 같은 측정값으로 설정되어 있지 않아 이 부분은 색상-크기-레이블 마크를 Score to 100 최대값으로 통일시켜주었다. 또한 불필요하게 들어가 있는 위도와 경도 필터는 제외해주었다.
수정 후
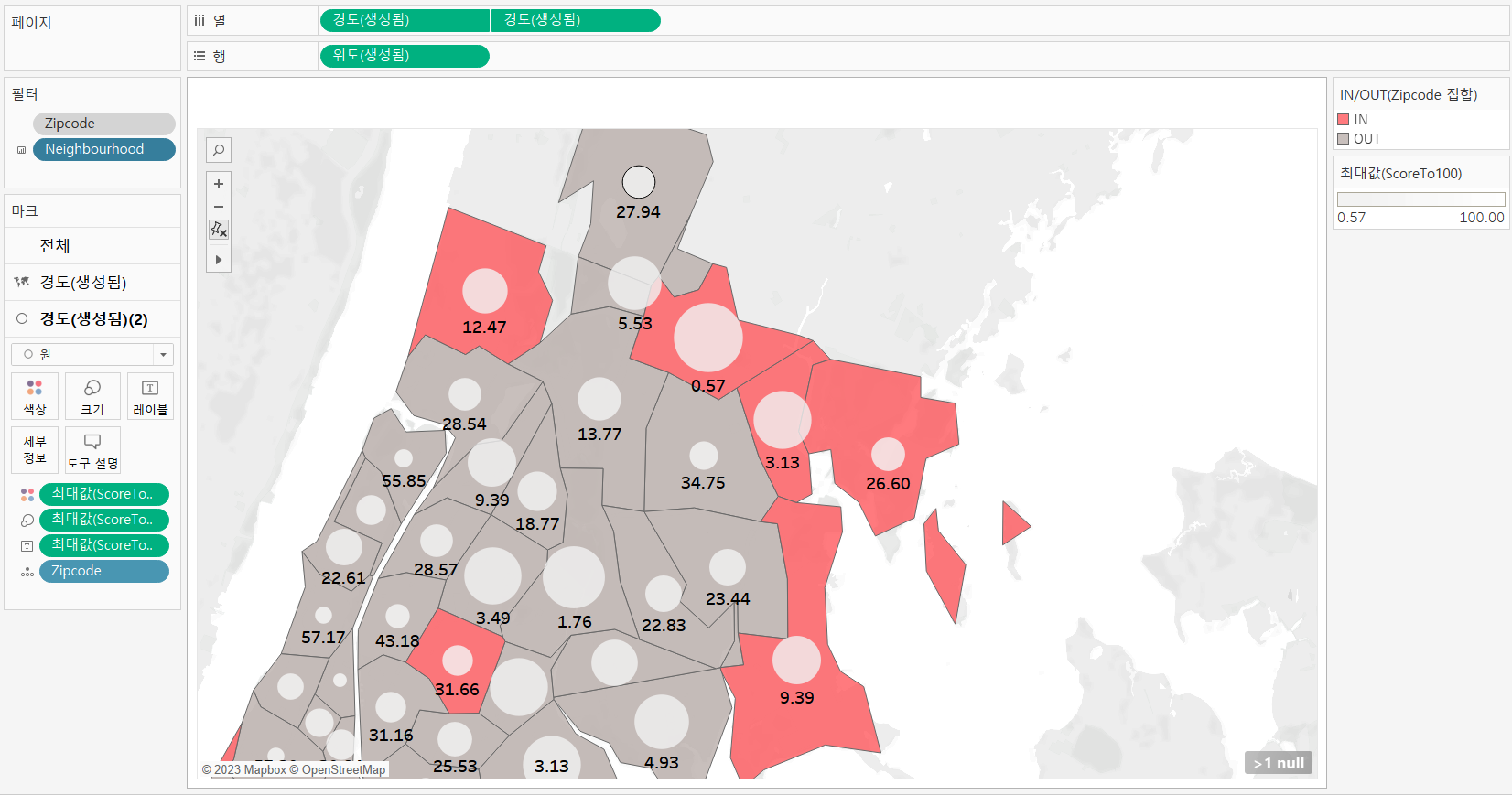
프로젝트를 할 때 생각보다 시행착오를 많이 겪었고 시간도 많이 소요되었다. 특히 데이터가 기대했던 것과 다른 결과를 보이는 경우가 많아서 차트를 마지막까지도 수정해야만 했다. 결과적으로 무슨 말을 하고 싶은지 "기획이 중요하다"는 것은 이제 말하기도 민망할 정도이고...
그리고 기존에는 도메인 지식과 더불어 이미 너무 잘 아는 데이터만 다뤘었기 때문에 이렇게 불친절하고 앞뒤가 안 맞는 것처럼 보이는 데이터를 접했을 때의 체감 난이도는 비교가 되지 않을 정도였다. 인하우스가 아닌 데이터 분석 대행사.. 생각보다 쉽지 않을 것 같다.
그래도 그룹, 집합, 필터 개념을 확실하게 다지고 오답노트까지 해보니 이번 주 내내 막막했던 부분은 자신감이 좀 생긴 것 같다!
>> 유데미 바로가기
>> STARTERS 취업 부트캠프 공식 블로그 보러가기
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터 분석 과정 학습 일지 리뷰로 작성되었습니다.
#유데미 #유데미코리아 #유데미큐레이션 #유데미부트캠프 #취업부트캠프 #스타터스부트캠프 #데이터시각화 #데이터분석 #데이터드리븐 #태블로
'유데미 스타터스 데이터 분석' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 8주차 학습 일지 (0) | 2023.04.02 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 7주차 학습 일지 (1) | 2023.03.26 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 5주차 학습 일지 (0) | 2023.03.12 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(4) (2) | 2023.03.10 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(3) (0) | 2023.03.10 |


댓글