2022.03.06 ~ 2022.03.10
5주차는 유데미 태블로 고수되기 과정이 끝나고 시계열 데이터 분석 과정을 진행했다. 그렇지만 지난 주에 중간 평가를 대비하느라 태블로 내용을 복습하지 않았고 6주차에는 오프라인 태블로 강의가 진행되기 때문에 이번 학습일지에서는 태블로 기본 개념을 정리하려 한다.
목차
블렌딩과 조인
클러스터링
그룹과 집합
LOD(Level Of Detail)
블렌딩과 조인
- 조인: 결합 후 집계
- 블렌딩: 집계 후 결합
조인은 일반적인 데이터베이스 구조에서 사용되는 개념과 동일하다. row 단위로 보조 테이블의 데이터가 붙는 방식이고 데이터를 불러오자마자 진행하게 된다.
반면 블렌딩은 집계의 단위가 먼저 정의된 후 보조 테이블의 데이터가 해당 집계 기준으로 붙는 방식이다.

블렌딩을 사용해야 하는 케이스는 다음과 같다.
주문 테이블과 주문 상세 테이블은 주문id를 기준으로 조인이 가능하다. 주문 상세 테이블의 데이터는 개별 상품 단위로 존재하기 때문인데, 이 조인 테이블을 월을 기준으로 월별 목표 매출액 테이블과 결합하고자 한다면 조인 테이블의 주문 상세 데이터는 roll up 되어버린다. 즉 상세 데이터가 유실된다.
태블로에서 확인한다면 조인 테이블에서 월을 기준으로 컬럼을 지정했기 때문에(선집계) 월별 목표 매출액 데이터를 블렌딩(후결합) 했을 때 월별로 잘 매칭된 것을 확인할 수 있다. 데이터가 결합되었다기보다는 필요한 데이터를 얹었다는 표현이 적절한 것 같다.
클러스터링
challenge 1
두개의 판매권역 중 어디가 더 실적이 좋은가? (3개의 지표 중 2개가 더 뛰어난 판매권역 선정하기)
- 도시별 평균 수익(높을수록 좋음)
- 도시별 평균 마케팅 비용(낮을수록 좋음)
- 도시별 평균 마케팅 투자 수익(ROMI=수익/마케팅 비용)
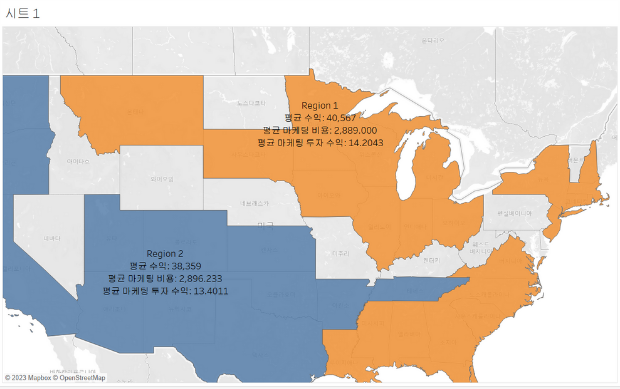
→ sales region 색상 구분, 사용자 지정 영역(그룹핑), 평균 수익, 평균 마케팅 비용, 평균 마케팅 투자 수익 라벨 추가
challenge 2
10개의 새로운 도시 중 마케팅 투자를 할만한 가치가 높은 최적의 도시는?
- x축: 마케팅 비용
- y축: 수익
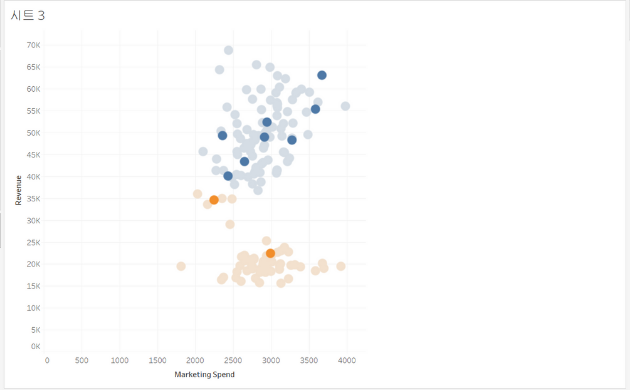
→ 클러스터링(마케팅 비용, 수익), 하이라이팅(10개의 새로운 도시)
클러스터링 고도화
마케팅 투자 수익은 인구 수와 상관관계가 있지 않을까? (세탁물은 인구 수에 비례한다)
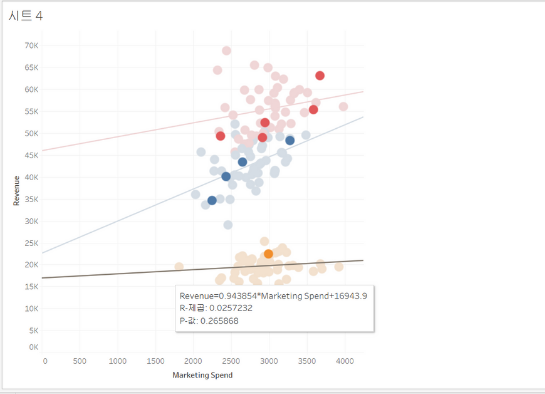
→ 클러스터링 차원 추가(인구수), 하이라이팅(10개의 새로운 도시), 추세선 추가
→ 노란색 그룹: 1달러 투자 시 0.94달러의 수익 발생 → 새로운 도시 중 노란색 그룹에 속한 상점은 더 이상 투자할 필요 없음
→ 파란색 그룹은 수익 자체는 낮지만 마케팅 비용 대비 수익이 높기 때문에 파란색 그룹에서 투자할 상점을 선택할 수 있음
그룹
4개 부서를 IT 그룹으로 만들기
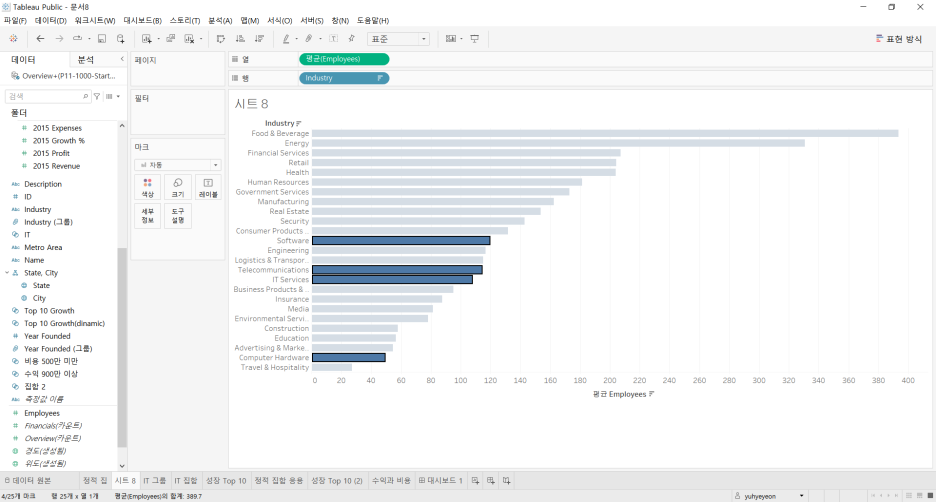
우클릭 > 그룹 만들기
결과
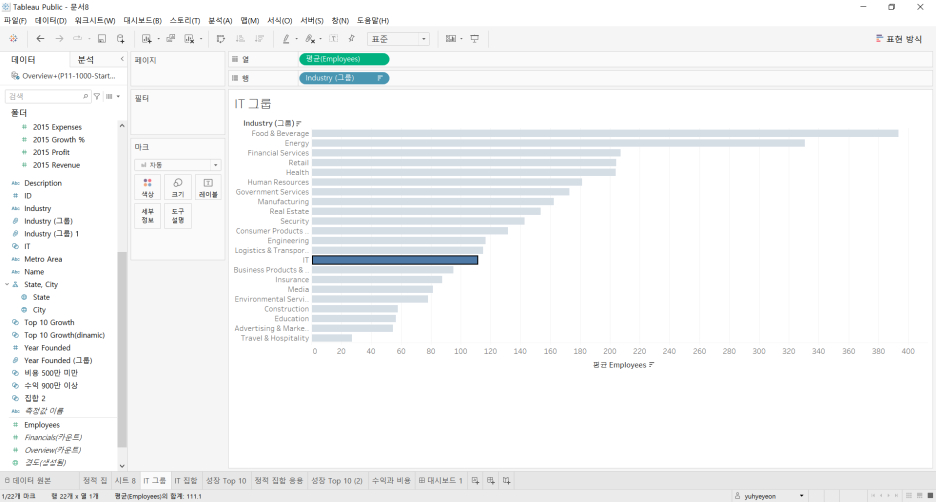
→ IT 그룹에 employee 평균 값 병합됨
집합
4개 부서를 IT 집합으로 만들기
우클릭 > 집합 만들기
결과
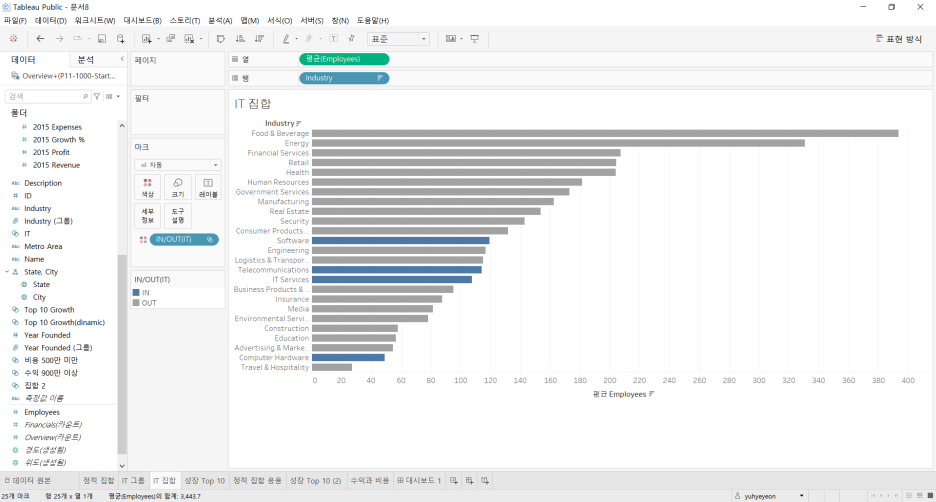
→ 4개 부서로 이루어진 IT 집합을 색상으로 강조(IN/OUT)
동적 집합(응용)
revenue가 900만 이상인 동적 집합 생성하기
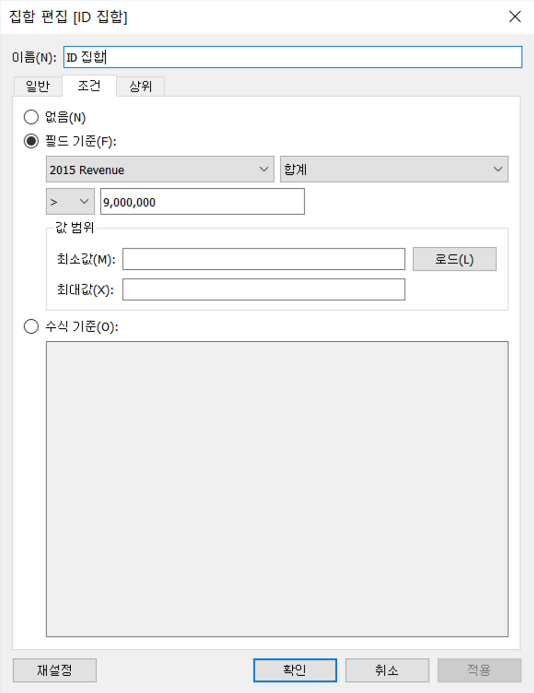
결과
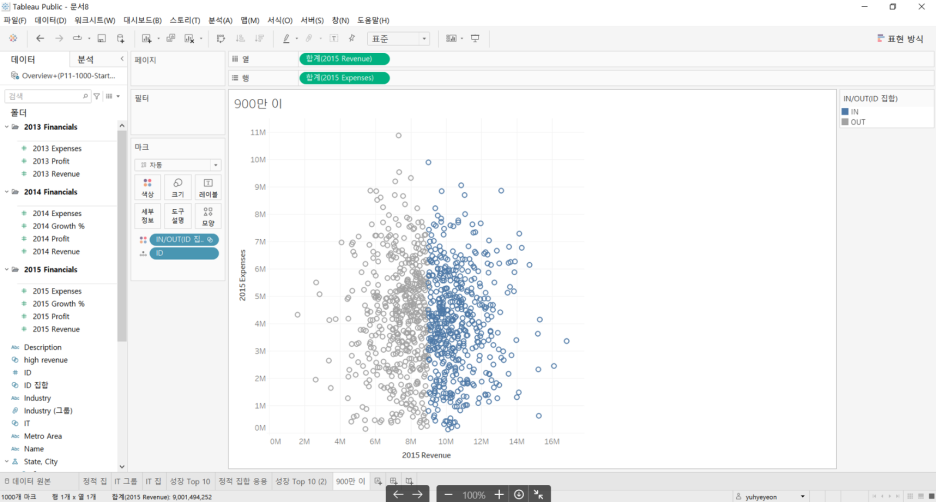
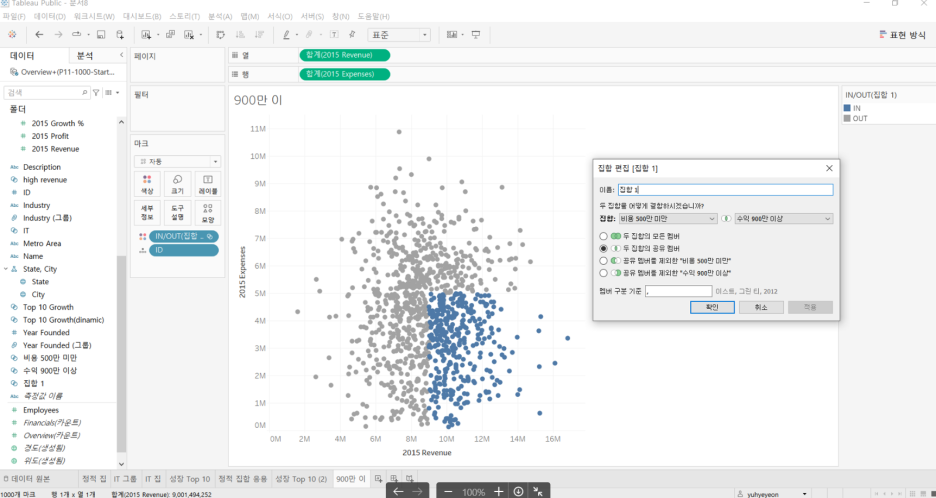
집합 결합(응용)
revenue가 900만 이상, expense가 500만 미만인 집합 결합하기
우클릭 > 결합된 집합 만들기
LOD(Level of Detail, 세부 수준 계산식)
- include: 상대 경로(하위 폴더로 이동)
- exclude: 상대 경로(상위 폴더로 이동)
- fixed: 절대 경로
레벨이 높을수록 데이터는 집계되어 있고, 레벨이 낮을수록 각 차원으로 값이 분화된다. 차원을 행, 열, 그리고 세부 정보에 추가할수록 레벨이 낮아진다. (세부 정보 → 시각화를 변화시키지 않으면서 레벨을 낮출 수 있는 방법)
LOD 1: Fixed
수식
{Fixed [기준 컬럼]: 집계함수([집계할 값])}
- 열: SUM(Sales)
- 행: 2nd Category
{Fixed [1st Category]: SUM([Sales])}
결과
|
1st Category
|
2nd Category
|
SUM(Sales)
|
Fixed for 1st Category
|
|
A
|
a
|
2000
|
5000
|
|
|
b
|
3000
|
5000
|
|
B
|
c
|
3000
|
10000
|
|
|
d
|
4000
|
10000
|
|
|
e
|
3000
|
10000
|
LOD 2: Include
수식
{Include [기준 컬럼]: 집계함수([집계할 값])}
- 열: SUM(Sales)
- 행: 1st Category
{Include [2nd Category]: average([Sales])}
결과
|
1st Category
|
SUM(Sales)
|
Include for 2nd Category
|
|
A
|
5000
|
2000
|
|
B
|
10000
|
3000
|
LOD 3: Exclude
수식
{Exclude [기준 컬럼]: 집계함수([집계할 값])}
- 열: SUM(Sales)
- 행: 2nd Category
{Exclude [1st Category]: SUM([Sales])}
결과
|
1st Category
|
2nd Category
|
SUM(Sales)
|
Exclude for 1st Category
|
|
A
|
a
|
2000
|
5000
|
|
|
b
|
3000
|
5000
|
|
B
|
c
|
3000
|
10000
|
|
|
d
|
4000
|
10000
|
|
|
e
|
3000
|
10000
|
이번 주는 묘하게 바쁜 주였다. 시계열 데이터 분석 강의는 초반에는 쉬엄쉬엄 가는 듯 했으나 statesmodels 라이브러리와 예측 모델에 대한 내용은 생소한데다 영어로 진행되는 강의를 따라가는 게 쉽지 않았다. 다음 주는 주차 별로 팀 랭킹이 있을 것이라 하니 더 적극적으로 참여해서 많이 배워가고 싶다. 목표를 단순화하고 당면한 과제에 집중하기!!
>> 유데미 바로가기
>> STARTERS 취업 부트캠프 공식 블로그 보러가기
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터 분석 과정 학습 일지 리뷰로 작성되었습니다.
#유데미 #유데미코리아 #유데미큐레이션 #유데미부트캠프 #취업부트캠프 #스타터스부트캠프 #데이터시각화 #데이터분석 #데이터드리븐 #태블로
'유데미 스타터스 데이터 분석' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 7주차 학습 일지 (1) | 2023.03.26 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 6주차 학습 일지 (1) | 2023.03.19 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(4) (2) | 2023.03.10 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(3) (0) | 2023.03.10 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지(2) (0) | 2023.03.09 |


댓글